Reference: |
To create a column reference in a request, you can:
- Preface the column number with a C in a non-FML request.
- Use the column number as an index in conjunction with a row label in an FML request. With this type of notation, you can specify a specific column, a relative column number, or a sequence or series of columns.
- Refer to a particular cell in an FML request using the notation E(r,c), where r is a row number and c is a column number.
In the following request with CNOTATION=ALL, the product of C1 and C2 does not calculate TRANSTOT times QUANTITY because the reformatting generates additional columns.
SET CNOTATION = ALL TABLE FILE VIDEOTRK SUM TRANSTOT/D12.2 QUANTITY/D12.2 AND COMPUTE PRODUCT = C1 * C2; BY TRANSDATE END
The output is:
TRANSDATE TRANSTOT QUANTITY PRODUCT --------- -------- -------- ------- 91/06/17 57.03 12.00 3,252.42 91/06/18 21.25 2.00 451.56 91/06/19 38.17 5.00 1,456.95 91/06/20 14.23 3.00 202.49 91/06/21 44.72 7.00 1,999.88 91/06/24 126.28 12.00 15,946.63 91/06/25 47.74 8.00 2,279.11 91/06/26 40.97 2.00 1,678.54 91/06/27 60.24 9.00 3,628.85 91/06/28 31.00 3.00 961.00
BY fields do not get a column reference, so the first column reference is for TRANSTOT with its original format, then the reformatted version. Next is QUANTITY with its original format and then the reformatted version. Last is the calculated value, PRODUCT.
Setting CNOTATION=PRINTONLY assigns column references to the output columns only. In this case, the product of C1 and C2 does calculate TRANSTOT times QUANTITY.
SET CNOTATION = PRINTONLY TABLE FILE VIDEOTRK SUM TRANSTOT/D12.2 QUANTITY/D12.2 AND COMPUTE PRODUCT = C1 * C2; BY TRANSDATE END
The output is:
TRANSDATE TRANSTOT QUANTITY PRODUCT --------- -------- -------- ------- 91/06/17 57.03 12.00 684.36 91/06/18 21.25 2.00 42.50 91/06/19 38.17 5.00 190.85 91/06/20 14.23 3.00 42.69 91/06/21 44.72 7.00 313.04 91/06/24 126.28 12.00 1,515.36 91/06/25 47.74 8.00 381.92 91/06/26 40.97 2.00 81.94 91/06/27 60.24 9.00 542.16 91/06/28 31.00 3.00 93.00
In the following request, the reformatting of fields generates additional columns in the internal matrix. In the second RECAP expression, note that because of the CNOTATION setting:
- TOTCASH(1) refers to total cash in displayed column 1.
- TOTCASH(2) refers to total cash in displayed column 2.
- The resulting calculation is displayed in column 2 of the row labeled CASH GROWTH(%).
- The RECAP value is only calculated for the column specified.
SET CNOTATION=PRINTONLY DEFINE FILE LEDGER CUR_YR/I5C=AMOUNT; LAST_YR/I5C=.87*CUR_YR - 142; END TABLE FILE LEDGER SUM CUR_YR/F9.2 AS 'CURRENT,YEAR' LAST_YR/F9.2 AS 'LAST,YEAR' FOR ACCOUNT 1010 AS 'CASH ON HAND' OVER 1020 AS 'DEMAND DEPOSITS' OVER 1030 AS 'TIME DEPOSITS' OVER BAR OVER RECAP TOTCASH/F9.2C= R1 + R2 + R3; AS 'TOTAL CASH' OVER " " OVER RECAP GROCASH(2)/F9.2C=100*TOTCASH(1)/TOTCASH(2) - 100; AS 'CASH GROWTH(%)' END
The output is:
CURRENT
YEAR | LAST
YEAR | |
CASH ON HAND | 8784.00 | 7216.00 |
DEMAND DEPOSITS | 4494.00 | 3483.00 |
TIME DEPOSITS | 7961.00 | 6499.00 |
-------- | -------- | |
TOTAL CASH | 21239.00 | 17198.00 |
CASH GROWTH(%) | 23.50 |
In this example, the RECAP calculation for ATOT occurs only for displayed columns 2 and 3, as specified in the request. No calculation is performed for displayed column 1.
SET CNOTATION=PRINTONLY DEFINE FILE LEDGER CUR_YR/I5C=AMOUNT; LAST_YR/I5C=.87*CUR_YR - 142; NEXT_YR/I5C=1.13*CUR_YR + 222; END TABLE FILE LEDGER SUM NEXT_YR/F9.2 CUR_YR/F9.2 LAST_YR/F9.2 FOR ACCOUNT 10$$ AS 'CASH' OVER 1100 AS 'ACCOUNTS RECEIVABLE' OVER 1200 AS 'INVENTORY' OVER BAR OVER RECAP ATOT(2,3)/I5C = R1 + R2 + R3; AS 'ASSETS ACTUAL' END
The output is:
NEXT_YR | CUR_YR | LAST_YR | |
CASH | 25992.00 | 21239.00 | 17198.00 |
ACCOUNTS RECEIVABLE | 21941.00 | 18829.00 | 15954.00 |
INVENTORY | 31522.00 | 27307.00 | 23329.00 |
-------- | -------- | -------- | |
ASSETS ACTUAL | 67,375 | 56,478 |
This example computes the change in cash (CHGCASH) for displayed columns 1 and 2.
SET CNOTATION=PRINTONLY DEFINE FILE LEDGER CUR_YR/I5C=AMOUNT; LAST_YR/I5C=.87*CUR_YR - 142; NEXT_YR/I5C=1.13*CUR_YR + 222; END TABLE FILE LEDGER SUM NEXT_YR/F9.2 CUR_YR/F9.2 LAST_YR/F9.2 FOR ACCOUNT 10$$ AS 'TOTAL CASH' LABEL TOTCASH OVER " " OVER RECAP CHGCASH(1,2)/I5SC = TOTCASH(*) - TOTCASH(*+1); AS 'CHANGE IN CASH' END
The output is:
NEXT_YR | CUR_YR | LAST_YR | |
TOTAL CASH | 25992.00 | 21239.00 | 17198.00 |
CHANGE IN CASH | 4,752 | 4,044 |
In this request, two RECAP expressions derive VARIANCEs (EVAR and WVAR) by subtracting values in four displayed columns (1, 2, 3, 4) in row three (PROFIT); these values are identified using cell notation (r,c).
SET CNOTATION=PRINTONLY TABLE FILE REGION SUM E_ACTUAL/F9.2 E_BUDGET/F9.2 W_ACTUAL/F9.2 W_BUDGET/F9.2 FOR ACCOUNT 3000 AS 'SALES' OVER 3100 AS 'COST' OVER BAR OVER RECAP PROFIT/I5C = R1 - R2; OVER " " OVER RECAP EVAR(1)/I5C = E(3,1) - E(3,2); AS 'EAST VARIANCE' OVER RECAP WVAR(3)/I5C = E(3,3) - E(3,4); AS 'WEST VARIANCE' END
The output is:
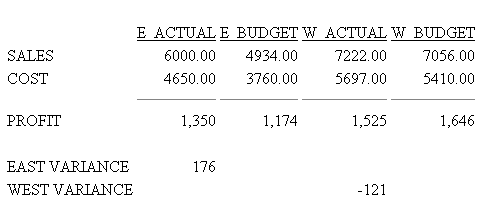
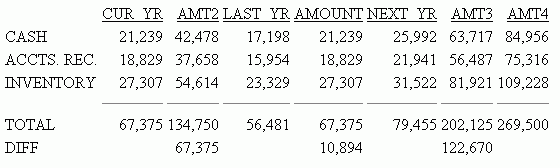
The following request has a field that is not printed, several reformatted fields and three calculated values. With SET CNOTATION=PRINTONLY, the column references result in correct output.
SET CNOTATION = PRINTONLY DEFINE FILE LEDGER CUR_YR/I5C=AMOUNT; LAST_YR/I5C=.87*CUR_YR - 142; NEXT_YR/I5C=1.13*CUR_YR + 222; END TABLE FILE LEDGER SUM NEXT_YR NOPRINT CUR_YR COMPUTE AMT2/D6 = AMOUNT *2; LAST_YR/D5 AMOUNT NEXT_YR COMPUTE AMT3/D6 = AMOUNT*3; COMPUTE AMT4/D6 = AMOUNT*4; FOR ACCOUNT 10$$ AS 'CASH' OVER 1100 AS 'ACCTS. REC.' OVER 1200 AS 'INVENTORY' OVER BAR OVER RECAP ATOT/I8C = R1 + R2 + R3; AS 'TOTAL' OVER RECAP DIFF(2,10,2)/D8 = ATOT(*) - ATOT(*-1); END
The output is:
The following request, sums TRANSTOT, QUANTITY, and TRANSCODE by TRANSDATE. TRANSTOT has the NOPRINT option, so it is not displayed on the report output. The request also calculates the following fields using COMPUTE commands:
- TTOT2, which has the same value as TRANSTOT and displays on the report output.
- UNIT_COST1, which is calculated by dividing column1 by column2.
- UNIT_COST2, which is calculated by dividing column1 by QUANTITY.
SET CNOTATION = ALL TABLE FILE VIDEOTRK SUM TRANSTOT/D7.2 NOPRINT QUANTITY/D7.2 TRANSCODE COMPUTE TTOT2/D7.2 = C1; COMPUTE UNIT_COST1/D7.2 = C1/C2; COMPUTE UNIT_COST2/D7.2 = C1/QUANTITY; BY TRANSDATE END
With this request, only CNOTATION=EXPLICIT produces the correct output. The following discussion illustrates why the EXPLICIT setting is needed.
With CNOTATION=ALL, all fields in the internal matrix are assigned column numbers. In particular, the request creates the following column references:
- C1 is TRANSTOT with its original format.
- C2 is TRANSTOT with format D7.2.
- C3 is QUANTITY with its original format.
- C4 is QUANTITY with format D7.2.
- C5 is TRANSCODE.
UNIT_COST1 is C1/C2. These column numbers have both been assigned to TRANSTOT, so UNIT_COST1 always equals 1. UNIT_COST2 is C1 (TRANSTOT) divided by QUANTITY. The output is:
TRANSDATE QUANTITY TRANSCODE TTOT2 UNIT_COST1 UNIT_COST2 --------- -------- --------- ----- ---------- ---------- 91/06/17 12.00 10 57.03 1.00 4.75 91/06/18 2.00 2 21.25 1.00 10.63 91/06/19 5.00 4 38.17 1.00 7.63 91/06/20 3.00 3 14.23 1.00 4.74 91/06/21 7.00 6 44.72 1.00 6.39 91/06/24 12.00 9 126.28 1.00 10.52 91/06/25 8.00 7 47.74 1.00 5.97 91/06/26 2.00 2 40.97 1.00 20.48 91/06/27 9.00 7 60.24 1.00 6.69 91/06/28 3.00 3 31.00 1.00 10.33
With CNOTATION = PRINTONLY, the field TRANSTOT, which has the NOPRINT option, is not assigned any column numbers. QUANTITY with its original format is not assigned a column number because it is not displayed on the report output. The reformatted QUANTITY field is displayed and is assigned a column number. Therefore, the request creates the following column references:
- C1 is QUANTITY with format D7.2.
- C2 is TRANSCODE.
UNIT_COST1 is C1/C2, QUANTITY/TRANSCODE. UNIT_COST2 is C1 (QUANTITY) divided by QUANTITY. Therefore, UNIT_COST2 always equals 1. The output is:
TRANSDATE QUANTITY TRANSCODE TTOT2 UNIT_COST1 UNIT_COST2 --------- -------- --------- ----- ---------- ---------- 91/06/17 12.00 10 12.00 1.20 1.00 91/06/18 2.00 2 2.00 1.00 1.00 91/06/19 5.00 4 5.00 1.25 1.00 91/06/20 3.00 3 3.00 1.00 1.00 91/06/21 7.00 6 7.00 1.17 1.00 91/06/24 12.00 9 12.00 1.33 1.00 91/06/25 8.00 7 8.00 1.14 1.00 91/06/26 2.00 2 2.00 1.00 1.00 91/06/27 9.00 7 9.00 1.29 1.00 91/06/28 3.00 3 3.00 1.00 1.00
With CNOTATION = EXPLICIT, the reformatted TRANSTOT field is explicitly referenced in the request, so it is assigned a column number even though it is not displayed. However, the TRANSTOT field with its original format is not assigned a column number. The QUANTITY field with its original format is not assigned a column number because it is not explicitly referenced in the request. The reformatted QUANTITY field is assigned a column number. Therefore, the request creates the following column references:
- C1 is TRANSTOT with format D7.2.
- C2 is QUANTITY with format D7.2.
- C3 is TRANSCODE.
UNIT_COST1 is C1/C2, TRANSTOT/QUANTITY. UNIT_COST2 is C1 (TRANSTOT) divided by QUANTITY. Therefore, UNIT_COST2 always equals UNIT_COST1. The output is:
TRANSDATE QUANTITY TRANSCODE TTOT2 UNIT_COST1 UNIT_COST2 --------- -------- --------- ----- ---------- ---------- 91/06/17 12.00 10 57.03 4.75 4.75 91/06/18 2.00 2 21.25 10.63 10.63 91/06/19 5.00 4 38.17 7.63 7.63 91/06/20 3.00 3 14.23 4.74 4.74 91/06/21 7.00 6 44.72 6.39 6.39 91/06/24 12.00 9 126.28 10.52 10.52 91/06/25 8.00 7 47.74 5.97 5.97 91/06/26 2.00 2 40.97 20.48 20.48 91/06/27 9.00 7 60.24 6.69 6.69 91/06/28 3.00 3 31.00 10.33 10.33
In the following request, CUR_YR has the NOPRINT option. The CHGCASH RECAP expression is supposed to subtract CUR_YR from LAST_YR and NEXT_YR.
SET CNOTATION = ALL DEFINE FILE LEDGER CUR_YR/I7C = AMOUNT; LAST_YR/I5C = .87*CUR_YR - 142; NEXT_YR/I5C = 1.13*CUR_YR + 222; END TABLE FILE LEDGER SUM CUR_YR/I5C NOPRINT LAST_YR NEXT_YR FOR ACCOUNT 10$$ AS 'TOTAL CASH ' LABEL TOTCASH OVER " " OVER RECAP CHGCASH(1,3)/I5SC=(TOTCASH(*) - TOTCASH(1)); AS 'CHANGE FROM CURRENT' END
When CNOTATION = ALL, C1 refers to the CUR_YR field with its original format, C2 refers to the reformatted value, C3 is LAST_YR, and C4 is NEXT_YR. Since there is an extra column and the RECAP only refers to columns 1 and 3, the calculation for NEXT_YR - CUR_YR is not performed. The output is:
LAST_YR NEXT_YR
------- -------
TOTAL CASH 17,195 25,991
CHANGE FROM CURRENT -4,044When CNOTATION = PRINTONLY, the CUR_YR field is not assigned any column number, so there is no column 3. Therefore, no calculations are performed. The output is:
LAST_YR NEXT_YR
------- -------
TOTAL CASH 17,195 25,991
CHANGE FROM CURRENTWhen CNOTATION = EXPLICIT, the reformatted version of the CUR_YR field is C1 because it is referenced in the request even though it is not displayed. Both calculations are performed correctly. The output is:
LAST_YR NEXT_YR
------- -------
TOTAL CASH 17,195 25,991
CHANGE FROM CURRENT -4,044 4,752
- BY fields are not assigned column numbers.
- ACROSS columns are assigned column numbers.
- Calculated fields are assigned column numbers.
- Column numbers outside
the range of the columns created in the request are allowed under
the following circumstances (and are treated as containing the value zero):
- When specified in a COMPUTE command issued after an ACROSS phrase.
- In a cell reference in an FML RECAP command.
In those cases, it is not possible to know in advance how many columns will be generated by the syntax. Using a column number outside of the range in any other context generates the following message:
(FOC258) FIELDNAME OR COMPUTATIONAL ELEMENT NOT RECOGNIZED: column