This topic provides an overview of Adabas and Adabas files, and includes a discussion of server concepts.
Adabas is a field-oriented DBMS. Data retrievals and updates are performed on a field-by-field basis.
Since Adabas data retrieval occurs at the field level rather than at the record level, your applications may be designed without consideration for the physical organization and maintenance of the record. Data is accessed in a variety of ways (in physical sequence, in logical sequence, or by Internal Sequence Numbers), thereby enabling you to tailor data access to address your specific needs.
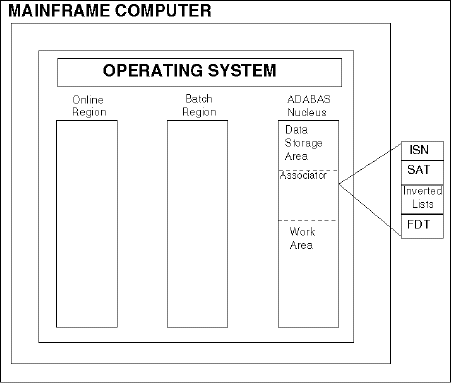
The Adabas DBMS consists of several components. The following is an illustration of the Adabas environment.
This table describes the components of the Adabas environment.
|
Component |
Description |
|---|---|
|
Operating System |
Set of programs (software) that control the operation of the computer (hardware). |
|
Online Region |
Part of the Dynamic Area of the computer. It is the section in which multiple jobs execute simultaneously. The Online Region is also known as the Foreground Region (applies only to TSO). |
|
Batch Region |
Part of the Dynamic Area of the computer. Jobs become a series of commands that are grouped together and processed in batches (applies only to batch jobs). |
|
Data Storage Area |
Contains the actual data. The data is stored in compressed form. |
|
Associator |
Stores relationships about the data. It contains the following components:
|
|
Work Area |
Is a "scratch pad" used by Adabas to build ISN lists and to sort and store records that your program requires. |
The Multi-Programming Module (MPM), the cornerstone of the Adabas Nucleus, contains the logic that enables multiple programs, both batch and online, to access Adabas databases simultaneously.
Each database has its own data storage area, associator, and work area, in addition to its own unique database number.
When accessing Adabas, the server uses logical files as the unit of data retrieval. An Adabas file is identified by a file number. The number is unique within each database.
All file and field documentation for the Adabas database can be stored in the Predict dictionary. The information about the data structure includes processing uses, file ownership, and field descriptions.
An Adabas file is defined with a set of indexes called descriptors. The Adabas term for these values, which reside in the File Associator Table, is inverted lists. Inverted lists contain the values of descriptors, a count of the total number of records in which each value appears, and the Internal Sequence Numbers (ISNs), in ascending order, associated with each occurrence.
Adabas utilities create and maintain an inverted list for each descriptor identified. These lists store data in an ascending sequence by the value of the key. A single file may have up to 256 inverted lists associated with it.
The descriptors are identified to speed data location and to retrieve specific, frequently required data from Adabas files. Of the available types of inverted lists, the Adapter for Adabas supports the following.
|
Inverted List |
Description |
|---|---|
|
Descriptors |
Key values associated with a single field (also called elementary field descriptors). |
|
Subdescriptors |
Key values associated with part of a single field. |
|
Superdescriptors |
Key values associated with all or part of two to twenty fields. |
|
Phonetic descriptors |
Alphabetic values associated with the first twenty bytes of the field value. |
|
Hyperdescriptors |
A value generated, based on a user-supplied algorithm. |
In the following text, descriptor refers to all five types of descriptors interchangeably, unless otherwise indicated.
Two or more files may be related in these ways:
Reference: |
Field description information for Adabas files is maintained in the FDT, which is part of the Adabas associator. Adabas uses this information when accessing files. The FDT includes the following information:
|
Field Information |
Description |
|---|---|
|
Field Level Indicator |
Denotes a hierarchical relationship between fields. In an Adabas record description the levels are 1, 2, 3, and so on. |
|
Adabas Field Name |
Two-character name used by Adabas to identify the field. This name is unique to the file. The first character must be alphabetic, and the second character can be alphabetic or numeric. Field names E0 through E9 are reserved for internal Adabas use. |
|
Standard Length |
Length of the field in bytes. |
|
Standard Format |
Format of the field. Refer to the table in Standard Formats for Adabas Fields for the acceptable formats and their meanings. |
|
Field Properties |
Indicates whether the field value is null suppressed (NU), the field is of fixed or variable length (FI), or if the field (which exists on a mainframe platform) is long alphanumeric (LA). |
|
Descriptor Status |
Indicates if the field is a descriptor, subdescriptor, superdescriptor, phonetic descriptor, hyperdescriptor, subfield, or superfield. |
|
Field Type |
Indicates if a field is a group (GR), multi-value (MU), or periodic group (PE). Multi-value fields and periodic groups are examples of multiply occurring fields. |
Typically, an Adabas FDT contains some, but not all, of the field characteristics discussed above. To view the FDT, Software AG provides the ADAREP report. See your Software AG documentation for more information on how to run the ADAREP report.
The external field name is in the Predict dictionary.
|
External Field Name |
32-byte name used in a Predict to identify the field. This name is unique to the file. |
The following table shows the acceptable standard formats for Adabas fields and their meanings.
|
Format |
Description |
|---|---|
A |
Alphanumeric data field with a maximum of 253 bytes (126 for descriptor fields). |
U |
Zoned decimal data field with a maximum of 29 bytes (signed, unpacked data). |
P |
Signed packed decimal data field with a maximum of 15 bytes. |
B |
Unsigned binary data field with a maximum of 126 bytes. |
F |
Single-precision, floating point data field that is always four bytes long. |
G |
Decimal, double-precision integer field with an eight-byte maximum. |
In the following example, the column on the left illustrates a partial Adabas FDT. The bold numbers on the left refer to the numbered annotations that follow:
PAY-FILE FIELD DESCRIPTION (from FDT) FIELD NAME (from DDM) 1. 01, PS, 08, P, NU, DE SSN 2. 01, PW, 04, P HOURLY_WAGE 3. 01, MI, PE MONTHLY_INFO 02, MH, 04, P MONTHLY_HOURS 02, MW, 04, P MONTHLY_WAGES 02, MT, 04, P MONTHLY_TAX 4. 01, PT, 04, P, DE, MU TAX 01, PC, 08, P, DE, MU CHILD_SSN
For more information about Adabas periodic groups (PE) and multi-value (MU) fields, see Mapping Adabas Files With Variable-Length Records and Repeating Fields.
Null-suppression is one of the methods Adabas employs to manage data storage. Only the fields within a record that contain data are stored. Fields containing blanks for alphabetic characters or zeros for numeric data are not stored. They are represented by a one-byte "empty field" character. When a procedure accesses a record containing a null-suppressed field, Adabas expands the field to its full length and includes the null values of blanks or zeros.
When the null-suppressed field is a descriptor or part of a superdescriptor, no entry is made for the record containing that field in the inverted list. It would not be productive to have the inverted list direct you to records in which the descriptor has no data.
A field with null-suppression appears with the NU attribute in the Adabas FDT.
Note that for the Server to support NULL (MISSING = ON) for an Adabas field, you must define the field in the Adabas FDT with the NC attribute.
Adabas includes two data definition options, Not Counted (NC) and Not Null or Null Value Not Allowed (NN), for providing SQL-compatible null representation for mainframe Adabas SQL Server (ESQ) by Software AG and other Structured Query Language (SQL) database query languages.
The NC and NN options cannot be applied to fields defined:
NC: SQL Null Value Option
Without the Not Counted (NC) option, a null value is either zero or blank depending on the field format.
With the NC option, zeros or blanks specified in the record buffer are interpreted according to the "null indicator" value: either as true zeros or blanks (that is, as "significant" nulls) or as undefined values (that is, as true SQL or "insignificant" nulls).
If the field defined with the NC option has no value specified in the record buffer, the field value is always treated as an SQL null.
Note: On the mainframe platform, subdescriptors and superdescriptors defined with NC=YES and MISSING=ON parameters cannot be used to search for the SQL NULL value, as that causes an Adabas RC 61.
NN: SQL Not Null Option
The Not Null or Null Value Not Allowed (NN) option may only be specified when the NC option is also specified for a data field. The NN option indicates that an NC field must always have a value (including zero or blank) defined; it cannot contain "no value".
The server uses a non-procedural language to create reports, graphs, and extract files. It also enables you to access data sources without knowing the details of the file structure or access method.
The server treats any data source as either a single-path or multi-path hierarchy. Graphically, information is laid out using an inverted tree structure, as in the following sample STAFF file. In the example, the letter I to the right of a field indicates an indexed field.
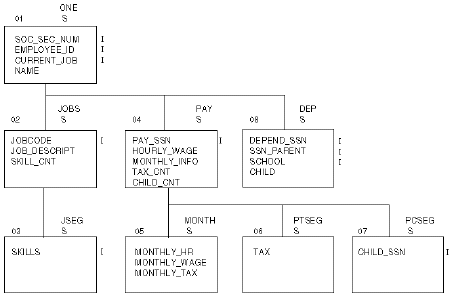
The most general information appears at the top, and the more specific information appears under it. Each box in the structure is referred to as a segment. A database can consist of one or more logically related segments.
When logically related information is retrieved using this database structure, multiple occurrences of each segment are created. Each occurrence of a segment is called a segment instance. Each Adabas database is equivalent to a collection of logically related segment instances.
The retrieval sequence of the segments is determined by the view of the structure, that is, the order of the segments from top to bottom and left to right. The segment at the top is the parent, or root, segment. The segments under the parent are the child, or descendant, segments.
Generally, parent and child segments have a one-to-many relationship. That is, a single parent has multiple occurrences of one child segment. However, the server also handles one parent-one instance only of a child segment.
Adabas uses specific concepts and techniques for organizing data. It holds data in logically distinct files that are interrelated using fields that share common formats and values called descriptors.
Within a single Adabas file, records that contain multiple occurrences of a field can vary in length and format. The following example illustrates an Adabas structure containing four separate files that are linked by common fields:
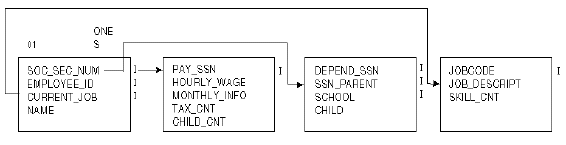
Many Adabas structures are more complex than the preceding example.
Descriptors are fields, partial fields, or groups of complete and partial fields used by Adabas to select records in a file. Adabas descriptors correspond to indexed fields.
There are five types of descriptors supported by the Adapter for Adabas:
All five types of descriptors are collectively referred to as "descriptors."
Consider the Adabas FDT for the STAFF file:
STAFF
FILE FDT
FIELD DESCRIPTION (from FDT) FIELD NAME (from Predict)
01, ES, 08, P, NU, DE SOC_SEC_NUM
01, EI, 06, A, NU, DE EMPLOYEE_ID
01, EJ, 03, A, DE CURRENT_JOB
01, EN, 24, A NAMENotice that SOC_SEC_NUM, EMPLOYEE_ID, and CURRENT_JOB are labeled as descriptors. Any one of these three fields can be used to search the STAFF file.
Adabas descriptors, superdescriptors, and subdescriptors must be declared in Master and Access Files in certain ways. For more information, see Mapping Adabas Descriptors.
Unless an Adabas file has multi-value fields or periodic groups, each field occurs once in each record. When describing an Adabas file, you do not need to describe all the fields in your Master File; just the fields you use. Note that if you choose a periodic group, all fields in the periodic group must be defined. A single simple Adabas file maps to a single segment on the server, and each field you use in the Adabas file becomes a field in the segment.
|
Adabas RECORD |
SEGMENT | ||
|---|---|---|---|
|
DB |
Name (in Predict) |
Field Name |
Alias |
ES |
SOC_SEC_NUM |
SOC_SEC_NUM |
ES |
EI |
EMPLOYEE_ID |
EMPLOYEE_ID |
EI |
EJ |
CURRENT_JOB |
CURRENT_JOB |
EJ |
EN |
NAME |
NAME |
EN |
There are two types of Adabas repeating fields:
An MU field is a single field that occurs a variable number of times in a record. It appears as type MU in an Adabas record description. Adabas supports up to 191 occurrences of MU fields per record.
A PE group is a group of contiguous fields that occur a variable number of times in a single record. It appears as type PE in an Adabas record description. Adabas supports up to 191 occurrences of PE fields per record. These component fields are regular fields or MU fields.
Note: The Adapter for Adabas supports the maximum number of occurrences of MU fields and PE groups allowed by Software AG.
When an Adabas file contains MU fields or PE groups, the repeating information occurs a variable number of times. The physical record length varies depending on how many times the repeating information actually appears.
More than one segment is needed to accurately describe an Adabas file with repeating data. The number of times the fields repeat is expressed in a counter field. For more information, see Mapping Adabas Files With Variable-Length Records and Repeating Fields.
| WebFOCUS |