
In this section: |
When Magnify is fed data to be stored as search content, it expects an incoming document in a specific format. Using Format Magnify, the WebFOCUS protocol is transformed by the Reporting Server into a document following these protocols. Using DataMigrator, the document is manually created and must adhere to these protocols. In iWay, the IEI Feed Agent converts the process flow output to adhere to those protocols. The incoming feed document can contain one or more records or search results.
The iWay Service Manager and the FORMAT MAGNIFY command can be used to extract, transform, and load data into the Magnify index library from various sources, such as databases, legacy systems, and transactional messages. Each document generated must be well-formed XML that adheres to the Magnify feed protocol. This section describes the required document format whether you are using the IEI Feed Agent in the iWay Service Manager or the FORMAT MAGNIFY command to feed data to Magnify.
Note: The IEI Feed Agent and FORMAT MAGNIFY command generate the final document in adherence with the Magnify protocols. However, the developer must prepare the data in accordance with these protocols.
The following image illustrates a well-formed XML document that adheres to the Magnify protocol specification.
In this section: |
Each incoming feed document that is indexed by Magnify requires a header and record element. These elements provide information, such as how the document should be fed to the index library and the type of document that is being indexed.
The header section contains the following document-level Magnify feed properties:
Contains one of the following values:
Important: It is a best practice to always index data using WF_INDEX_UNIQUE_KEY.
Is the source of the data to be fed to the search engine. If the library is not found, Magnify creates it dynamically. Magnify index libraries are created in the location specified by the magnify_root parameter configured in the WebFOCUS Administration Console. For more information, see the Magnify Security and Administration manual.
The record element contains attributes that define record-level Magnify feed properties and the content being indexed. The information contained in the record element varies for each protocol. However, the record element defines the following for each protocol:
The action attribute specifies how to apply each record found in the incoming document to a Magnify index and contains one of the following values:
The mime type attribute defines the type of content to process in the content section of the record. This value is specific to each protocol.
Note: This attribute can be defined per record when more than one record is sent in a single document.
Specifies the default record ID in the Magnify index library. In addition, this URL is used by the Magnify interface as follows:
Note: The URL must be encoded.
The document and record-level properties are defined in the IEI Feed Agent properties tab in the iWay Designer tool and in the FORMAT MAGNIFY ENGINE SET statements. The base URL is defined by the BASE URL property in both the IEI Feed Agent and FORMAT MAGNIFY statements. The query string parameters appended to the records URL attribute are generated by user-defined properties of the IEI Feed Agent or in the FORMAT MAGNIFY alias naming conventions.
Defines the actual document being indexed with Magnify. The attribute encoding must be set to base64binary and the content assigned within this node must be base64 encoded.
The content document is generated using the iWay Process Transformation described in Supporting Information for iWay or the FORMAT MAGNIFY alias naming convention.
In this section: Reference: |
Depending on the type of data being indexed within the content document, Magnify requires the data to be packaged following a specific protocol. Magnify uses the following protocols for accepting documents from a feed process:
The record protocol is used for structured and semi-structured data sources like database records. The mime type attribute of the record must be set to text/plain. The document inserted into the content section is also an XML document with a Target_Root element and a HEAD section. The following elements are contained in the HEAD section:
Note: The BODY element is stored as IBI_CONTENT in the Magnify index library, which can be accessed using tools, such as Lucene Luke.
The following image illustrates a decoded document that can be indexed using the record protocol.
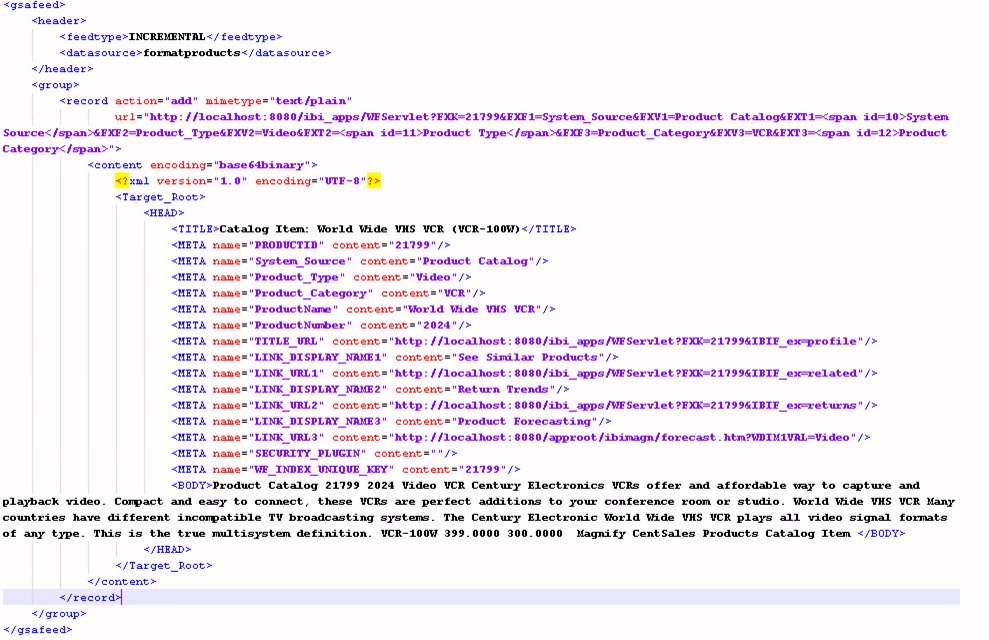
Note: Magnify requires base64 encoded content and an encoded record URL.
The URL protocol is used for web-accessible files and is recommended for larger files. Magnify fetches the document and reads in and indexes the content. The mime type attribute of the record must be set to application/openurl. Magnify locates the file based on the URL attribute value of the record. If a URL cannot be accessed or indexed, it is logged in the application server log files. The document inserted into the content section is also an XML document with an ENCODEDDOCUMENT root element containing HEAD, DOCUMENT, and AUTHENTICATION sections.
The following elements are contained in the HEAD section:
The Document section contains the following attributes:
The content element is empty, since Magnify fetches the content based on the URL attribute value of the record.
The Authentication section contains the wwwauthenticateuserid and wwwauthenticatepassword attributes, which are used to access the domain where the document is located.
The contents of the document indexed are stored as IBI_CONTENT in the Magnify index library which can be accessed using tools, such as Lucene Luke.
The following image illustrates a decoded document that can be indexed using the URL protocol.
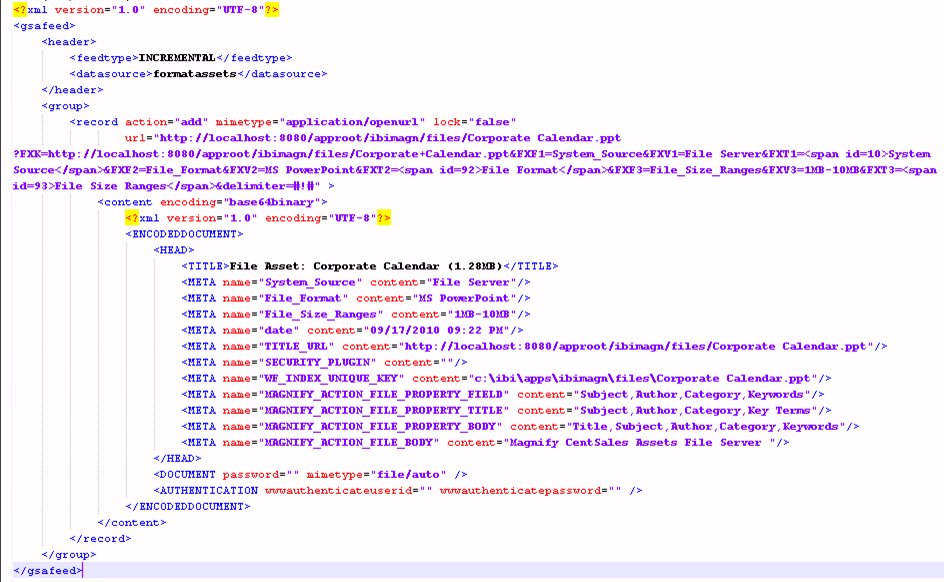
Note: Magnify requires base64 encoded content and an encoded record URL.
The document protocol is used when files can be embedded into the document that is being indexed. Magnify reads in and indexes the content of the document. The mime type attribute of the record must be set to application/encodeddocument.
The document inserted into the content section is an XML document with an ENCODEDDOCUMENT root element containing a HEAD and DOCUMENT section.
The following elements are contained in the HEAD section:
The DOCUMENT section contains attributes about the embedded file within the Document tags. Encoding must be set to base64binary. The mime type must be set to file/auto. The fetched document is passed to the Magnify parser to process various file types based on information natively found in the document header. A password is required if the file is password protected. The password is used to read the file for indexing and is optional.
The contents of the document indexed are stored as IBI_CONTENT in the Magnify index library which can be accessed using tools such as Lucene Luke.
The following image illustrates a decoded document that can be indexed using the Document protocol.

Note: Magnify requires base64 encoded content and an encoded record URL.
Embedding files into the Magnify feed document can be done using the file object in the iWay Service Manager tool. For more information on the iWay Process Flow, see Supporting Information for iWay. The embedded file must be base64 encoded. This results in a double-encoded document prior to being sent to Magnify as part of the base64 encoding of the document within the content section.
Magnify search results adhere to the Google Search Protocol and can be consumed by other applications, such as a dashboard. Magnify currently supports the following XML tags:
For more information on the Google Search Protocol tags, see http://code.google.com/apis/searchappliance/documentation/46/xml_reference.html#results_xml.
| WebFOCUS |