Reporting Language Enhancements
WebFOCUS is a complete information control system with
comprehensive features for retrieving and analyzing data. It enables
you to create reports quickly and easily. It also provides facilities
for creating highly complex reports, but its strength lies in the simplicity
of the request language. You can begin with simple queries and progress
to complex reports as you learn about additional facilities.
Release 8.1 includes the Reporting Language new features available
in Server Release 7.7 Version 06.
xSpecifying the Sort Order in Amper Auto-Prompting Single-Select and Multi-Select Dynamic Lists
As of Release 8.1 Version 05, in Amper Auto-Prompting
single-select and multi-select dynamic lists, you can specify the
sort order of the values retrieved from data sources using the SORT
parameter processing option. The default sort order is ascending.
x
Syntax: How to Add a Dynamic Single-Select List of Values
'&variable.(FIND return_fieldname [,display_fieldname] IN datasource[|SORT=sortoption]).[description.]'
where:
- &variable
Is the variable, including the ampersand (&), for which
you are supplying a list of values.
- return_fieldname
Is the name of the field containing the possible variable
values that are returned to the FOCEXEC.
- display_fieldname
Is the name of the field containing the possible variable
values that are displayed in the auto-prompt form.
- datasource
Is the data source that contains the fields specified in return_fieldname and display_fieldname.
If the fields reside in a cross-reference file of a data source
used in a join, use the data source name that contains the fields.
- sortoption
Provides the ability to specify how to sort the values returned
for a dynamic list. Valid values are:
- ASCENDING,
which sorts in low to high order. This is the default value when
sort processing is not specified.
- DESCENDING, which sorts in high to low order.
- description
Is an optional description of the variable.
Example: Adding a Dynamic Single-Select List of Values in Descending Sort Order
The
following provides a list of values that are valid for the product
name field. This list is populated with values from the CENTORD
data source. The user can select only one value from the list.
-<description>This procedure reports on Inventory </description>
-<description>by state, storename and product number. </description>
-<heading> Please specify a state, storename and product name: </heading>
-DEFAULT &STATE=NY
TABLE FILE CENTORD
SUM QTY_IN_STOCK BY STATE BY STORENAME BY PROD_NUM
ON TABLE SUBHEAD
"Inventory Report"
WHERE STATE EQ '&STATE.2 letters for US State.'
WHERE STORENAME EQ '&STORENAME.(eMart,TV City,Web Sales).Store Name.'
WHERE PROD_NUM EQ '&PROD_NUM.(FIND PROD_NUM,PRODNAME IN CENTORD|SORT=DESCENDING).Product Name.'
END
x
Syntax: How to Add a Dynamic Multiselect List of Values
&variable.({AND|OR}(FIND return_fieldname [,display_fieldname] IN datasource[|SORT=sortoption])).[description.]where:
- &variable
Is the variable, including the ampersand (&), for which
you are supplying a list of values.
- return_fieldname
Is the name of the field containing the possible variable
values that are returned to the FOCEXEC.
- display_fieldname
Is the name of the field containing the possible variable
values that are displayed in the auto-prompt form.
- datasource
Is the data source that contains the fields specified in return_fieldname and display_fieldname.
If the fields reside in a cross-reference file of a data source
used in a join, use the data source name that contains the fields.
- sortoption
Provides the ability to specify how to sort the values returned
for a dynamic list. Valid values are:
- ASCENDING,
which sorts in low to high order. This is the default value when
sort processing is not specified.
- DESCENDING, which sorts in high to low order.
- description
Is an optional description of the variable.
Example: Adding a Dynamic Multiselect List of Values in Descending Sort Order
The
following provides a list of values that are valid for the state
field. This list is populated with values from the CENTORD data
source. The user can select more than one value from the list.
-<description>This procedure reports on Inventory </description>
-<description>by store code, state and product name. </description>
-<heading> Please specify a storename, state and product name: </heading>
TABLE FILE CENTORD
SUM QTY_IN_STOCK BY STORE_CODE BY STATE BY PRODNAME
ON TABLE SUBHEAD
"Inventory Report"
WHERE STORE_CODE EQ &STORE_CODE.(OR(FIND STORE_CODE,STORENAME
IN CENTORD|SORT=DESCENDING)).Store Name.
WHERE STATE EQ &STATE.(OR(CA,IL,MA,NY,NJ,FL,TX)).2 letters for US State.
WHERE PRODNAME EQ '&PRODNAME.(FIND PRODNAME IN CENTORD).Product Name.'
END
xControlling Column Title Underlining Using a StyleSheet Attribute
As of Release 8.1 Version 05, the TITLELINE attribute
allows you to control whether column titles are underlined for report
output.
x
Syntax: How to Control Column Title Underlining Using a StyleSheet Attribute
TYPE={REPORT|TITLE}, TITLELINE = (ON|OFF|SKIP)where:
- ON
- Underlines column titles. ON is the default value.
- OFF
- Replaces the underline with a blank line.
- SKIP
- Omits both the underline and the line on which the underline
would have displayed.
Example: Controlling Column Title Underlining Using a StyleSheet Attribute
The following request has a BY and an
ACROSS field.
TABLE FILE GGSALES
SUM UNITS BY PRODUCT
ACROSS REGION
ON TABLE SET PAGE-NUM OFF
ON TABLE SET STYLE *
TYPE=REPORT, TITLELINE=ON, GRID=OFF, FONT=ARIAL,$
INCLUDE=endeflt.sty,$
END
With the default
value (ON) for TITLELINE, the column titles are underlined.
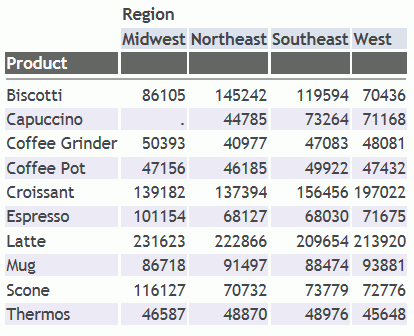
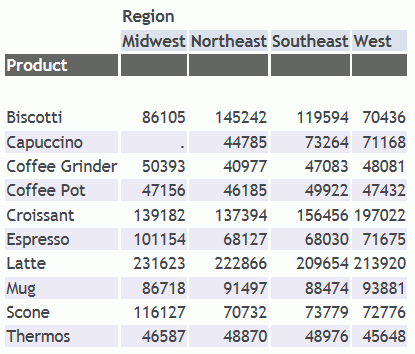
With TITLELINE=OFF, the column titles
are not underlined, but the blank line where the underlines would
have been is still there.
With TITLELINE=SKIP, both the underlines
and the blank line are removed.
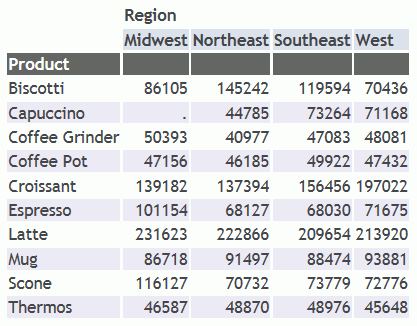
xPreventing Visual Overflow
At times, the size defined for
the USAGE format of a field may be too small to fit the actual data
to be displayed. In previous releases, this scenario would cause asterisks
(***) to display in the report output in place of the actual value.
Situations that cause this scenario include:
- If the display value
is larger than the defined display format.
- If a value is aggregated,
the summed value does not fit into the space that was allotted for
the column by the USAGE format of the field.
x
Syntax: How to Prevent Visual Overflow
SET EXTENDNUM = {ON|OFF|AUTO}
where:
- ON
-
Displays all numbers in full, regardless
of the USAGE format defined.
- OFF
-
Displays asterisks when the value does
not fit in the space allotted by the USAGE format. This is the legacy
behavior.
- AUTO
-
Applies an ON or
OFF setting based on output format and SQUEEZE settings, as shown
in the following table.
|
Format
|
SQUEEZE Setting
|
EXTENDNUM
|
|---|
| PDF, PS, DHTML,
PPT, PPTX | ON
OFF | ON
OFF |
| HTML, EXL2K, XLSX
| N/A
| ON
|
| BINARY, ALPHA
| N/A
| OFF
|
| WP, other delimited formats
| N/A
| OFF
|
AUTO is the default value.
x
Reference: Usage Notes for SET EXTENDNUM
Invoking SET EXTENDNUM=ON may
change the report layout in the following ways.
Changes in report layout:
- With styled formats
(PDF, PS, DHTML, HTML, EXL2K, XLSX, PPT, PPTX), the width of the
report is expanded to accommodate the width of the data columns.
This may change the placement of the overall report on the defined
page and in some instances cause columns to overflow to a new page.
- For PDF, DHTML, PPT,
and PPTX, the setting SQUEEZE ON will ensure that the alignment
within each column is retained.
- For HTML, EXL2K,
and XLSX, the alignment will automatically be retained regardless
of SQUEEZE settings.
- With unstyled formats
(WP), the columns are not adjusted to fit the new values, which
may cause misalignment of data columns.
Changed behavior in operating systems where the defined number format is not supported:
- Integers larger than
2GB cannot display on 32-bit machines. Therefore, such integers
on these machines will display incorrect values.
- Floating-point numbers
(types F and D) that require more than 31 digits to print correctly
will continue to display asterisks. For example, a field with usage
D33.30 and a value of 10.0 will print as asterisks because it needs
30 zeros to the right of the decimal point and two digits to the
left.
xDynamically Scaling HTML Report Output
The AUTOFIT parameter can be activated to dynamically
scale HTML reports and charts horizontally to fill the entire container
(window or frame) within your portal pages and HTML pages, as shown
in the following image.
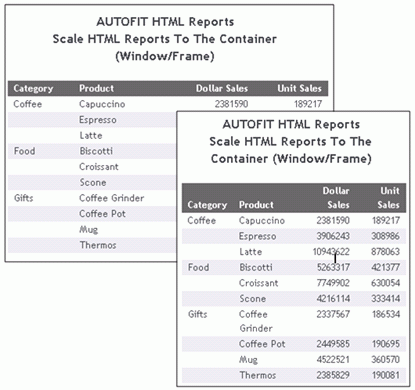
For more information on the AUTOFIT parameter, see the Developing
Reporting Applications manual.
xEmbedded Images in Microsoft Excel (XLSX) Workbooks
The XLSX workbooks can contain embedded images in fixed
positions in each of the WebFOCUS report areas including headers,
footers, and data cells. Additionally, graphs can be placed on individual
worksheets within compound workbooks, as shown in the following
image.
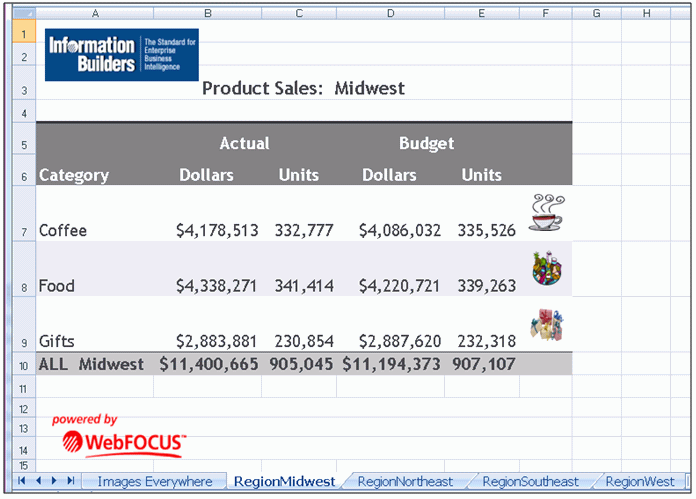
xAbility to Change Default Font Style for FORMAT XLSX
The default and available fonts for each output format
are defined in the fontmap.xml file maintained within the Reporting
Server. Prior to Release 8.1 Version 03, the definitions for DHTML
also covered the Microsoft Office formats (XLSX, PPT, PPTX). As of
Release 8.1 Version 03, font definitions for format XLSX can be
defined separately, allowing ease in customizing the look and feel
of your XLSX workbooks. WebFOCUS uses Arial as the default font.
Use this feature to change the default font to match the Microsoft Office
standard font, Calibri, or your corporate standard. For more information
on font maps, see the Creating Reports With WebFOCUS Language manual.
xMicrosoft PowerPoint Presentation File Format (PPTX)
The PPTX file format can contain reports, graphs, and
images with WebFOCUS styling features, as well as populate PowerPoint
templates containing preset Slide Masters, styling, and other business
content, as shown in the following image.
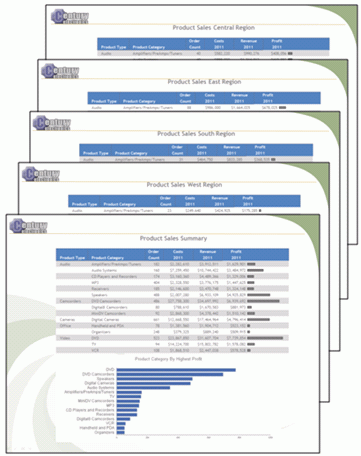
xUsing PowerPoint PPTX Display Format
With PowerPoint (PPTX), Microsoft® introduced enhanced
functionality in a new presentation file format. WebFOCUS Release
8.1 introduces the capability to retrieve data from any WebFOCUS
supported data source and to generate a PPTX presentation for data
analysis and distribution.
The PPTX format generates fully styled
reports in binary display format, which uses the same binary technology
that is used for XLSX. When PPTX is specified as the output format, a
PowerPoint presentation with a single slide that includes the report
is created.
The WebFOCUS procedure generates a new presentation containing
your defined report elements, such as headings and subtotals, as
well as StyleSheet syntax, such as conditional styling and drill
downs.
Additionally, you can add multiple graphs and images to a PowerPoint
presentation. The PowerPoint output format can contain a variety
of graphs positioned anywhere on a slide to create a visual layout.
x
Using PowerPoint PPTX Templates
You can place report output on a specific slide in a
PowerPoint template. This enables you to populate existing presentations
with preset Slide Masters, styling, and other business content.
PowerPoint design templates (POTX) and PowerPoint macro-enabled templates
(POTM) are stored on the server and can be distributed automatically
with ReportCaster.
x
Syntax: How to Create PowerPoint PPTX Report Output
ON TABLE {PCHOLD|HOLD|SAVE} [AS name] FORMAT PPTX
[TEMPLATE {'template.potx'|'template.potm'} SLIDENUMBER n]
where:
- name
-
Is the name of the PowerPoint output
file.
- template
-
Is the name of the PowerPoint template
file. The template file must have at least one blank slide and must
be saved as a .POTX or .POTM extension on your WebFOCUS Reporting
Server application directory.
Note: Since different extensions are supported
for PowerPoint templates, it is recommended that you include the
extension in the name of your template.
- n
-
Is the number of the slide on which to
place the report output. This number is optional if the template
has only one slide.
Example: Using a PowerPoint PPTX Template
The following request against
the GGSALES data source inserts a WebFOCUS report into a PowerPoint
PPTX template named mytemplate.potx which is stored in the application directory:
TABLE FILE GGSALES
HEADING
" "
" "
" "
" "
" "
SUM DOLLARS UNITS CATEGORY
BY REGION
ON TABLE SET PAGE-NUM NOLEAD
ON TABLE NOTOTAL
ON TABLE PCHOLD FORMAT PPTX TEMPLATE 'mytemplate.potx' SLIDENUMBER 3
ON TABLE SET HTMLCSS ON
ON TABLE SET STYLE *
TYPE=REPORT, FONT=ARIAL, SIZE=10,$
TYPE=HEADING, image=gglogo.gif, POSITION=(0.000000 0.000000),$
ENDSTYLE
END
The output
is:
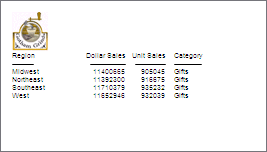
xWebFOCUS Client Amper Autoprompt Internal Processing
The performance and security of the WebFOCUS Release
8.1 Amper Autoprompt facility has been improved because the WebFOCUS
Client no longer uses XSLT templates to create the JavaScript for
the Autoprompt HTML page.
As of WebFOCUS Release 8.1, the WebFOCUS Client uses the XML
returned by the Reporting Server to create the JavaScript for the
Autoprompt HTML page. The autoprompt_top.xslt and autoprompt_top_checked.xslt
templates have been converted to the new Release 8.1 implementation.
Contact Customer Support Services if, prior to Release 8.1, you
created and are using a custom XSLT template or if you have a business need
to request conversion for one of the legacy Autoprompt templates:
autoprompt.xslt, autoprompt_checked.xslt, or autoprompt_simple.xslt.
xAutomatically Sizing an HTML HFREEZE Report
An AUTO option has been added
to the SCROLLHEIGHT command for use with the HTML HFREEZE reporting
feature. The AUTO option automatically sizes the HFREEZE report
within the browser page or the frame within the page.
When the browser is manually resized
after initial display of the HFREEZE report, the HFREEZE report
size remains the same. Select the browser refresh option to reload
the HFREEZE report, which will run the JavaScript that calculates
the HFREEZE report size within the current page or frame.
x
Syntax: How to Create a Scrollable Area in an HTML Report
TYPE=REPORT,HFREEZE={OFF|ON|TOP|BOTTOM},[SCROLLHEIGHT={AUTO|nn[.n]}], $
where:
- SCROLLHEIGHT=AUTO
-
Automatically sizes the HFREEZE report
within the browser page or the frame within the page.
- nn[.n]
-
Is the height, in inches, of the scrollable
area. The default is 4 inches.
xRolling Up Calculations on Summary Rows
Using
SUMMARIZE and RECOMPUTE, you can recalculate values at sort field
breaks, but these calculations use the detail data to calculate
the value for the summary line.
Using the ROLL. operator in conjunction with another prefix operator
on a summary line recalculates the sort break values using the values
from summary lines generated for the lower level sort break.
The operator combinations supported are:
- ROLL.SUM. (same as
ROLL.). Alphanumeric fields are supported with SUM. This returns
either the first or last value according to the SUMPREFIX parameter.
- ROLL.AVE.
- ROLL.MAX. (supported
with alphanumeric fields as well as numeric fields)
- ROLL.MIN. (supported
with alphanumeric fields as well as numeric fields)
- ROLL.FST. (supported
with alphanumeric fields as well as numeric fields)
- ROLL.LST. (supported
with alphanumeric fields as well as numeric fields)
- ROLL.CNT.
- ROLL.ASQ.
ROLL.prefix on a summary line indicates
that the prefix operation will be performed on the summary values
from the next lowest level of summary command.
If the ROLL. operator is used without another prefix operator,
it is treated as a SUM. Therefore, if the summary command for the
lowest BY field specifies AVE., and the next higher specifies ROLL.,
the result will be the sum of the averages. To get the average of
the averages, you would use ROLL.AVE at the higher level.
Note: With SUMMARIZE and SUB-TOTAL, the same
calculations are propagated to all higher level sort breaks.
x
Syntax: How to Roll Up Summary Values
BY field {SUMMARIZE|SUBTOTAL|SUB-TOTAL|RECOMPUTE} [ROLL.][prefix1.]
[field1 field2 ...|*] [ROLL.][prefix2.] [fieldn ...]
Or:
BY field
ON field {SUMMARIZE|SUBTOTAL|SUB-TOTAL|RECOMPUTE} ROLL.[prefix.]
[field1 field2 ...|*]
where:
- ROLL.
-
Indicates that the summary values should
be calculated using the summary values from the next lowest level
summary command.
- field
-
Is a BY field in the request.
- prefix1, prefix2
-
Are prefix operators to use for the summary
values. Can be one of the following operators: SUM. (the default
operator if none is specified), AVE., MAX., MIN., FST., LST., CNT.,
ASQ.
- field1
field2 fieldn
-
Are fields to be summarized.
- *
-
Indicates that all fields, numeric and
alphanumeric, should be included on the summary lines. You can either
use the asterisk to display all columns or reference the specific
columns you want to display.
Example: Rolling Up an Average Calculation
The following request against the GGSALES data source contains
two sort fields, REGION and ST. The summary command for REGION applies
the AVE. operator to the sum of the units value for each state.
TABLE FILE GGSALES
SUM UNITS AS 'Inventory '
BY REGION
BY ST
ON REGION SUBTOTAL AVE. AS 'Average'
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE SET PAGE NOPAGE
END
On the output, the UNITS values for each state are averaged
to calculate the subtotal for each region. The UNITS values for
each state are also used to calculate the average for the grand
total row.
Region State Inventory
------ ----- ----------
Northeast CT 37234
MA 35720
NY 36248
Average Northeast
36400
West CA 75553
WA 40969
Average West
58261
TOTAL 45144 The following
version of the request adds a summary command for the grand total
line that includes the ROLL. operator:
TABLE FILE GGSALES
SUM UNITS AS 'Inventory '
BY REGION
BY ST
ON REGION SUBTOTAL AVE. AS 'Average'
WHERE DATE GE 19971001
WHERE REGION EQ 'West' OR 'Northeast'
ON TABLE SUBTOTAL ROLL.AVE. AS ROLL.AVE
ON TABLE SET PAGE NOPAGE
END
On the output, the UNITS values for each state are averaged
to calculate the subtotal for each region, and those region subtotal
values are used to calculate the average for the grand total row:
Region State Inventory
------ ----- ----------
Northeast CT 37234
MA 35720
NY 36248
Average Northeast
36400
West CA 75553
WA 40969
Average West
58261
ROLL.AVE 47330
Example: Propagating Rollups to Higher Level Sort Breaks
The following request against the GGSALES data source
has three BY fields. The SUBTOTAL command for the PRODUCT sort field
specifies AVE., and the SUMMARIZE command for the higher level sort
field, REGION, specifies ROLL.AVE.
TABLE FILE GGSALES
SUM UNITS
BY REGION
BY PRODUCT
BY HIGHEST DATE
WHERE DATE GE 19971001
WHERE REGION EQ 'Midwest' OR 'Northeast'
WHERE PRODUCT LIKE 'C%'
ON PRODUCT SUBTOTAL AVE.
ON REGION SUMMARIZE ROLL.AVE. AS ROLL.AVE
ON TABLE SET PAGE NOPAGE
END
On the output, the detail rows for
each date are used to calculate the average for each product. Because
of the ROLL.AVE. at the region level, the averages for each product
are used to calculate the averages for each region, and the region
averages are used to calculate the average for the grand total line:
Region Product Date Unit Sales
------ ------- ---- ----------
Midwest Coffee Grinder 1997/12/01 4648
1997/11/01 3144
1997/10/01 1597
*TOTAL PRODUCT Coffee Grinder 3129
Coffee Pot 1997/12/01 1769
1997/11/01 1462
1997/10/01 2346
*TOTAL PRODUCT Coffee Pot 1859
Croissant 1997/12/01 7436
1997/11/01 5528
1997/10/01 6060
*TOTAL PRODUCT Croissant 6341
ROLL.AVE Midwest 3776
Northeast Capuccino 1997/12/01 1188
1997/11/01 2282
1997/10/01 3675
*TOTAL PRODUCT Capuccino 2381
Coffee Grinder 1997/12/01 1536
1997/11/01 1399
1997/10/01 1315
*TOTAL PRODUCT Coffee Grinder 1416
Coffee Pot 1997/12/01 1442
1997/11/01 2129
1997/10/01 2082
*TOTAL PRODUCT Coffee Pot 1884
Croissant 1997/12/01 4291
1997/11/01 6978
1997/10/01 4741
*TOTAL PRODUCT Croissant 5336
ROLL.AVE Northeast 2754
TOTAL 3265
x
Reference: Usage Notes for ROLL.
- ROLL.prefix on
a summary line indicates that the prefix operation will be performed
on the summary values from the next lowest level of summary command.
- If no summary command
was issued at the level below the ROLL., and no other operator was
used in conjunction with the ROLL., a SUM. will be calculated. If
the lower level had no summary command and ROLL. was used with another
prefix operator (for example, ROLL.AVE.), the specified prefix operator
will be used. For example, ROLL.AVE. will become AVE.
- CNT. prefix shows
the number of data lines displayed, which is not affected by MULTILINES.
- ROLL.CNT. prefix shows
the number of summary lines displayed, which is affected by MULTILINES.
xSimplified Character Functions
New character functions have been developed that make
it easier to understand and enter the required arguments. These
functions have streamlined parameter lists, similar to those used
by SQL functions. In some cases, these simplified functions provide
slightly different functionality than previous versions of similar
functions.
The simplified functions do not have an output argument. Each
function returns a value that has a specific data type.
When used in a request against a relational data source, these
functions are optimized (passed to the RDBMS for processing).
Note:
- The simplified character
functions are supported in Dialogue Manager.
- The simplified character
functions are not supported in WebFOCUS Maintain.
x
CHAR_LENGTH: Returning the Length in Characters of a String
The CHAR_LENGTH function returns the length, in characters, of
a string. In Unicode environments, this function uses character
semantics, so that the length in characters may not be the same
as the length in bytes. If the string includes trailing blanks,
these are counted in the returned length. Therefore, if the format
source string is type An, the returned value
will always be n.
x
Syntax: How to Return the Length of a String in Characters
CHAR_LENGTH(source_string)
where:
- source_string
-
Alphanumeric
Is the string whose length is returned.
The data type
of the returned length value is Integer.
Example: Returning the Length of a String
The following request against
the EMPLOYEE data source creates a virtual field named LASTNAME
of type A15V that contains the LAST_NAME with the trailing blanks
removed. It then uses CHAR_LENGTH to return the number of characters.
DEFINE FILE EMPLOYEE
LASTNAME/A15V = RTRIM(LAST_NAME);
END
TABLE FILE EMPLOYEE
SUM LAST_NAME NOPRINT AND COMPUTE
NAME_LEN/I3 = CHAR_LENGTH(LASTNAME);
BY LAST_NAME
ON TABLE SET PAGE NOPAGE
END
The output is:
LAST_NAME NAME_LEN
--------- --------
BANNING 7
BLACKWOOD 9
CROSS 5
GREENSPAN 9
IRVING 6
JONES 5
MCCOY 5
MCKNIGHT 8
ROMANS 6
SMITH 5
STEVENS 7
x
DIGITS: Converting a Number to a Character String
Given a number, DIGITS converts it to a character string
of the specified length. The format of the field that contains the
number must be Integer.
x
Syntax: How to Convert a Number to a Character String
DIGITS(number,length)
where:
- number
-
Integer
Is the number to be converted, stored in a
field with data type Integer.
- length
-
Integer between
1 and 10
Is the length of the returned
character string. If length is longer than the number of
digits in the number being converted, the returned value is padded
on the left with zeros. If length is shorter than the number
of digits in the number being converted, the returned value is truncated
on the left.
Example: Converting a Number to a Character String
The following request against
the WF_RETAIL_LITE data source converts -123.45 and ID_PRODUCT to
character strings:
DEFINE FILE WF_RETAIL_LITE
MEAS1/I8=-123.45;
DIG1/A6=DIGITS(MEAS1,6) ;
DIG2/A6=DIGITS(ID_PRODUCT,6) ;
END
TABLE FILE WF_RETAIL_LITE
PRINT MEAS1 DIG1
ID_PRODUCT DIG2
BY PRODUCT_SUBCATEG
WHERE PRODUCT_SUBCATEG EQ 'Flat Panel TV'
ON TABLE SET PAGE NOPAGE
END
The output
is:
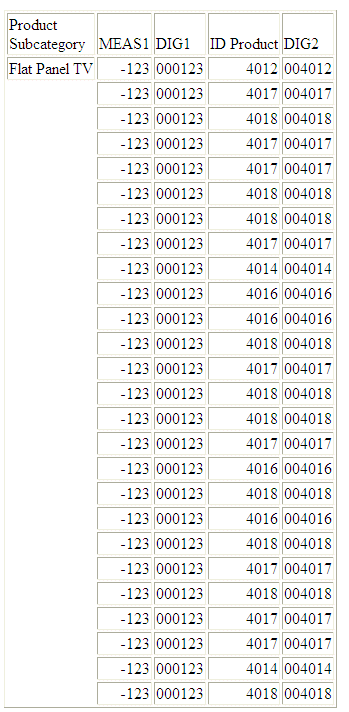
x
Reference: Usage Notes for DIGITS
- Only I Format numbers
will be converted. D, P, and F formats generate error messages and
should be converted to I before using the DIGITS function. The limit
for the number that can be converted is 2GB.
- Negative integers
are turned into positive integers.
- Integer formats with
decimal places are truncated.
- DIGITS is not supported
in Dialogue Manager.
x
LPAD: Left-Padding a Character String
LPAD uses a specified character and output length to
return a character string padded on the left with that character.
x
Syntax: How to Pad a Character String on the Left
LPAD(string, out_length, pad_character)
where:
- string
-
Fixed length
alphanumeric
Is a string to pad on the
left side.
- out_length
-
Integer
Is the length of the output string after padding.
- pad_character
-
Fixed length
alphanumeric
Is a single character to
use for padding.
Example: Left-Padding a String
In the following request against the
WF_RETAIL data source, LPAD left-pads the PRODUCT_CATEGORY column
with @ symbols:
DEFINE FILE WF_RETAIL
LPAD1/A25 = LPAD(PRODUCT_CATEGORY,25,'@');
DIG1/A4 = DIGITS(ID_PRODUCT,4);
END
TABLE FILE WF_RETAIL
SUM DIG1 LPAD1
BY PRODUCT_CATEGORY
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=DATA,FONT=COURIER,SIZE=11,COLOR=BLUE,$
END
The output is:

x
Reference: Usage Notes for LPAD
- To use the single
quotation mark as the padding character, you must double it and
enclose the two single quotation marks within single quotation marks (LPAD(COUNTRY,
20,''''). You can use an amper variable in quotation marks for this parameter,
but you cannot use a field, virtual or real.
- Input can be fixed
or variable length alphanumeric.
- Output, when optimized
to SQL, will always be data type VARCHAR.
- If the output is
specified as shorter than the original input, the original data
will be truncated, leaving only the padding characters. The output
length can be specified as a positive integer or an unquoted &variable
(indicating a numeric).
x
LOWER: Returning a String With All Letters Lowercase
The LOWER function takes a source string and returns a string
of the same data type with all letters translated to lowercase.
x
Syntax: How to Return a String With All Letters Lowercase
LOWER(source_string)
where:
- source_string
-
Alphanumeric
Is the string to convert to lowercase.
The returned
string is the same data type and length as the source string.
Example: Converting a String to Lowercase
In the
following request against the EMPLOYEE data source, LOWER converts
the LAST_NAME field to lowercase and stores the result in LOWER_NAME:
TABLE FILE EMPLOYEE
PRINT LAST_NAME AND COMPUTE
LOWER_NAME/A15 = LOWER(LAST_NAME);
ON TABLE SET PAGE NOPAGE
END
The output is:
LAST_NAME LOWER_NAME
--------- ----------
STEVENS stevens
SMITH smith
JONES jones
SMITH smith
BANNING banning
IRVING irving
ROMANS romans
MCCOY mccoy
BLACKWOOD blackwood
MCKNIGHT mcknight
GREENSPAN greenspan
CROSS cross
x
LTRIM: Removing Blanks From the Left End of a String
The LTRIM function removes all blanks from the left end of a
string.
x
Syntax: How to Remove Blanks From the Left End of a String
LTRIM(source_string)
where:
- source_string
-
Alphanumeric
Is the string to trim on the left.
The data type
of the returned string is AnV, with the same maximum length as the source
string.
Example: Removing Blanks From the Left End of a String
In
the following request against the MOVIES data source, the DIRECTOR
field is right-justified and stored in the RDIRECTOR virtual field.
Then LTRIM removes leading blanks from the RDIRECTOR field:
DEFINE FILE MOVIES
RDIRECTOR/A17 = RJUST(17, DIRECTOR, 'A17');
END
TABLE FILE MOVIES
PRINT RDIRECTOR AND
COMPUTE
TRIMDIR/A17 = LTRIM(RDIRECTOR);
WHERE DIRECTOR CONTAINS 'BR'
ON TABLE SET PAGE NOPAGE
END
The output is:
RDIRECTOR TRIMDIR
--------- -------
ABRAHAMS J. ABRAHAMS J.
BROOKS R. BROOKS R.
BROOKS J.L. BROOKS J.L.
x
POSITION: Returning the First Position of a Substring in a Source String
The POSITION function returns the first position (in characters)
of a substring in a source string.
x
Syntax: How to Return the First Position of a Substring in a Source String
POSITION(pattern, source_string)
where:
- pattern
-
Alphanumeric
Is the substring whose position you want to
locate. The string can be as short as a single character, including
a single blank.
- source_string
-
Alphanumeric
Is the string in which to find the pattern.
The data type
of the returned value is Integer.
Example: Returning the First Position of a Substring
In
the following request against the EMPLOYEE data source, POSITION
determines the position of the first capital letter I in LAST_NAME
and stores the result in I_IN_NAME:
TABLE FILE EMPLOYEE
PRINT LAST_NAME AND COMPUTE
I_IN_NAME/I2 = POSITION('I', LAST_NAME);
ON TABLE SET PAGE NOPAGE
END The output is:
LAST_NAME I_IN_NAME
--------- ---------
STEVENS 0
SMITH 3
JONES 0
SMITH 3
BANNING 5
IRVING 1
ROMANS 0
MCCOY 0
BLACKWOOD 0
MCKNIGHT 5
GREENSPAN 0
CROSS 0
x
RTRIM: Removing Blanks From the Right End of a String
The RTRIM function removes all blanks from the right end of a
string.
x
Syntax: How to Remove Blanks From the Right End of a String
RTRIM(source_string)
where:
- source_string
-
Alphanumeric
Is the string to trim on the right.
The data type
of the returned string is AnV, with the same maximum length as the source
string.
Example: Removing Blanks From the Right End of a String
The
following request against the MOVIES data source creates the field
DIRSLASH, that contains a slash at the end of the DIRECTOR field.
Then it creates the TRIMDIR field, which trims the trailing blanks
from the DIRECTOR field and places a slash at the end of that field:
TABLE FILE MOVIES
PRINT DIRECTOR NOPRINT AND
COMPUTE
DIRSLASH/A18 = DIRECTOR|'/';
TRIMDIR/A17V = RTRIM(DIRECTOR)|'/';
WHERE DIRECTOR CONTAINS 'BR'
ON TABLE SET PAGE NOPAGE
END
On the output, the slashes show that
the trailing blanks in the DIRECTOR field were removed in the TRIMDIR
field:
DIRSLASH TRIMDIR
-------- -------
ABRAHAMS J. / ABRAHAMS J./
BROOKS R. / BROOKS R./
BROOKS J.L. / BROOKS J.L./
x
SUBSTRING: Extracting a Substring From a Source String
The SUBSTRING function extracts a substring from a source string.
If the ending position you specify for the substring is past the
end of the source string, the position of the last character of
the source string becomes the ending position of the substring.
x
Syntax: How to Extract a Substring From a Source String
SUBSTRING(source_string, start_position, length_limit)
where:
- source_string
-
Alphanumeric
Is the string from which to extract the substring.
It can be a field, a literal in single quotation marks ('), or
a variable.
- start_position
-
Integer
Is the starting position of the substring in source_string.
If the position is 0, it is treated as 1. If the position is negative,
the starting position is counted backward from the end of source_string.
- length_limit
-
Integer
Is the limit for the length of the substring.
The ending position of the substring is calculated as start_position + length_limit -
1. If the calculated position beyond the end of the source string,
the position of the last character of source_string becomes
the ending position.
The data type of the returned substring is AnV.
Example: Extracting a Substring From a Source String
In
the following request, POSITION determines the position of the first
letter I in LAST_NAME and stores the result in I_IN_NAME. SUBSTRING
then extracts three characters beginning with the letter I from
LAST_NAME, and stores the results in I_SUBSTR.
TABLE FILE EMPLOYEE
PRINT
COMPUTE
I_IN_NAME/I2 = POSITION('I', LAST_NAME); AND
COMPUTE
I_SUBSTR/A3 =
SUBSTRING(LAST_NAME, I_IN_NAME, I_IN_NAME+2);
BY LAST_NAME
ON TABLE SET PAGE NOPAGE
END The output is:
LAST_NAME I_IN_NAME I_SUBSTR
--------- --------- --------
BANNING 5 ING
BLACKWOOD 0 BL
CROSS 0 CR
GREENSPAN 0 GR
IRVING 1 IRV
JONES 0 JO
MCCOY 0 MC
MCKNIGHT 5 IGH
ROMANS 0 RO
SMITH 3 ITH
3 ITH
STEVENS 0 ST
x
RPAD: Right-Padding a Character String
RPAD uses a specified character and output length to
return a character string padded on the right with that character.
x
Syntax: How to Pad a Character String on the Right
RPAD(string, out_length, pad_character)
where:
- string
-
Alphanumeric
Is a string to pad on the right side.
- out_length
-
Integer
Is the length of the output string after padding.
- pad_character
-
Alphanumeric
Is a single character to use for padding.
Example: Right-Padding a String
In the following request against the
WF_RETAIL data source, RPAD right-pads the PRODUCT_CATEGORY column
with @ symbols:
DEFINE FILE WF_RETAIL
RPAD1/A25 = RPAD(PRODUCT_CATEGORY,25,'@');
DIG1/A4 = DIGITS(ID_PRODUCT,4);
END
TABLE FILE WF_RETAIL
SUM DIG1 RPAD1
BY PRODUCT_CATEGORY
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE=DATA,FONT=COURIER,SIZE=11,COLOR=BLUE,$
END
The output is:
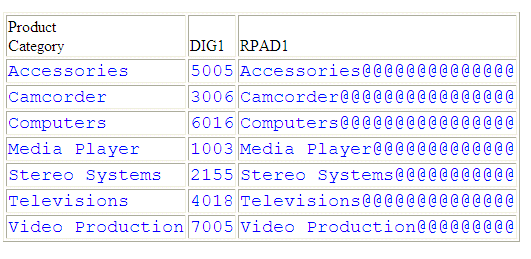
x
Reference: Usage Notes for RPAD
- The input string
can be data type AnV, VARCHAR, TX, and An.
- Output can only be
AnV or An.
- When working with
relational VARCHAR columns, there is no need to trim trailing spaces
from the field if they are not desired. However, with An and AnV
fields derived from An fields, the trailing spaces are part of the
data and will be included in the output, with the padding being
placed to the right of these positions. You can use TRIM or TRIMV
to remove these trailing spaces prior to applying the RPAD function.
x
TOKEN: Extracting a Token From a String
The TOKEN function extracts a token (substring) based
on a token number and a delimiter character.
x
Syntax: How to Extract a Token From a String
TOKEN(string, delimiter, number)
where:
- string
-
Fixed length
alphanumeric
Is the character string from
which to extract the token.
- delimiter
-
Fixed length
alphanumeric
Is a single character delimiter.
- number
-
Integer
Is the token number to extract.
Example: Extracting a Token From a String
TOKEN
extracts the second token from the PRODUCT_SUBCATEG column, where
the delimiter is the letter P:
DEFINE FILE WF_RETAIL_LITE
TOK1/A20 =TOKEN(PRODUCT_SUBCATEG,'P',2);
END
TABLE FILE WF_RETAIL_LITE
SUM TOK1 AS Token
BY PRODUCT_SUBCATEG
ON TABLE SET PAGE NOPAGE
END
The output is:
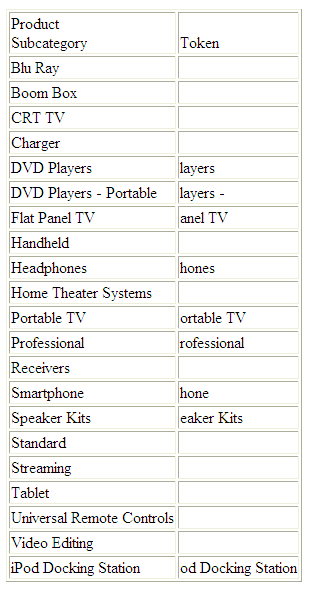
x
TRIM_: Removing Leading Characters, Trailing Characters, or Both From a String
The TRIM_ function removes all occurrences of a single character
from either the beginning of a string, the end of a string, or both.
x
Syntax: How to Remove Leading Characters, Trailing Characters, or Both From a String
TRIM_(trim_where, trim_character, source_string)
where:
- trim_where
-
Keyword
Defines where to trim the source string. Valid
values are:
-
LEADING, which removes leading occurrences.
-
TRAILING, which removes trailing occurrences.
-
BOTH, which removes leading and trailing occurrences.
- trim_character
-
Alphanumeric
Is a single character, enclosed in single quotation
marks ('), whose occurrences are to be removed from source_string.
For example, the character can be a single blank (‘ ‘).
- source_string
-
Alphanumeric
Is the string to be trimmed.
The data type of the
returned string is AnV.
Example: Trimming a Character From a String
In
the following request, TRIM_ removes leading occurrences of the
character ‘B’ from the DIRECTOR field:
TABLE FILE MOVIES
PRINT DIRECTOR AND
COMPUTE
TRIMDIR/A17 = TRIM_(LEADING, 'B', DIRECTOR);
WHERE DIRECTOR CONTAINS 'BR'
ON TABLE SET PAGE NOPAGE
END
The output is:
DIRECTOR TRIMDIR
-------- -------
ABRAHAMS J. ABRAHAMS J.
BROOKS R. ROOKS R.
BROOKS J.L. ROOKS J.L.
x
UPPER: Returning a String With All Letters Uppercase
The UPPER function takes a source string and returns a string
of the same data type with all letters translated to uppercase.
x
Syntax: How to Return a String With All Letters Uppercase
UPPER(source_string)
where:
- source_string
-
Alphanumeric
Is the string to convert to uppercase.
The returned
string is the same data type and length as the source string.
Example: Converting Letters to Uppercase
In the
following request, LCWORD converts LAST_NAME to mixed case. Then
UPPER converts the LAST_NAME_MIXED field to uppercase:
DEFINE FILE EMPLOYEE
LAST_NAME_MIXED/A15=LCWORD(15, LAST_NAME, 'A15');
LAST_NAME_UPPER/A15=UPPER(LAST_NAME_MIXED) ;
END
TABLE FILE EMPLOYEE
PRINT LAST_NAME_UPPER AND FIRST_NAME
BY LAST_NAME_MIXED
WHERE CURR_JOBCODE EQ 'B02' OR 'A17' OR 'B04';
ON TABLE SET PAGE NOPAGE
END
The output is:
LAST_NAME_MIXED LAST_NAME_UPPER FIRST_NAME
--------------- --------------- ----------
Banning BANNING JOHN
Blackwood BLACKWOOD ROSEMARIE
Cross CROSS BARBARA
Mccoy MCCOY JOHN
Mcknight MCKNIGHT ROGER
Romans ROMANS ANTHONY
xSimplified Date and Date-Time Functions
New date and date-time functions have been developed
that make it easier to understand and enter the required arguments.
These functions have streamlined parameter lists, similar to those
used by SQL functions. In some cases, these simplified functions
provide slightly different functionality than previous versions
of similar functions.
The simplified functions do not have an output argument. Each
function returns a value that has a specific data type.
When used in a request against a relational data source, these
functions are optimized (passed to the RDBMS for processing).
Standard date and date-time formats refer to YYMD and HYYMD syntax
(dates that are not stored in alphanumeric or numeric fields). Dates
not in these formats must be converted before they can be used in
the simplified functions. Literal date-time values can be used with
the DT function.
All arguments can be either literals, field names, or amper variables.
x
DTADD: Incrementing a Date or Date-Time Component
Given a date in standard date or date-time format, DTADD
returns a new date after adding the specified number of a supported
component. The returned date format is the same as the input date
format.
x
Syntax: How to Increment a Date or Date-Time Component
DTADD(date, component, increment)
where:
- date
-
Date or date-time
Is the date or date-time value to be incremented.
- component
-
Keyword
Is the component to
be incremented. Valid components (and acceptable values) are:
- YEAR (1-9999)
- QUARTER (1-4)
- MONTH (1-12)
- WEEK (1-53). This
is affected by the WEEKFIRST setting.
- DAY (of the Month,
1-31)
- HOUR (0-23)
- MINUTE (0-59)
- SECOND (0-59)
- increment
-
Integer
Is the value (positive or negative) to add
to the component.
Example: Incrementing the DAY Component of a Date
The following request against
the WF_RETAIL data source adds three days to the employee date of
birth:
DEFINE FILE WF_RETAIL
NEWDATE/YYMD = DTADD(DATE_OF_BIRTH, DAY, 3);
MGR/A3 = DIGITS(ID_MANAGER, 3);
END
TABLE FILE WF_RETAIL
SUM MGR NOPRINT DATE_OF_BIRTH NEWDATE
BY MGR
ON TABLE SET PAGE NOPAGE
END
The output
is:
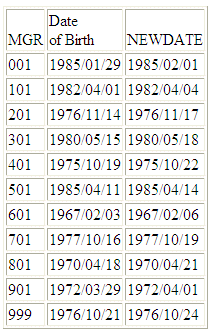
x
Reference: Usage Notes for DTADD
- Each element must
be manipulated separately. Therefore, if you want to add 1 year
and 1 day to a date, you need to call the function twice, once for
YEAR (you need to take care of leap years) and once for DAY. The
simplified functions can be nested in a single expression or created
and applied in separate DEFINE or COMPUTE expressions.
- With respect to parameter
validation, DTADD will not allow anything but a standard date or
a date-time value to be used in the first parameter.
- The increment is
not checked, and the user should be aware that decimal numbers are
not supported and will be truncated. Any combination of values that
increases the YEAR beyond 9999 returns the input date as the value,
with no message. If the user receives the input date when expecting
something else, it is possible there was an error.
x
DTDIFF: Returning the Number of Component Boundaries Between Date or Date-Time Values
Given two dates in standard date or date-time formats,
DTDIFF returns the number of given component boundaries between
the two dates. The returned value has integer format for calendar
components or double precision floating point format for time components.
x
Syntax: How to Return the Number of Component Boundaries
DTDIFF(end_date, start_date, component)
where:
-
end_date
-
Date or date-time
Is the ending date in either standard date
or date-time format. If this date is given in standard date format,
all time components are assumed to be zero.
- start_date
-
Date or date-time
Is the starting date in either standard date
or date-time format. If this date is given in standard date format,
all time components are assumed to be zero.
- component
-
Keyword
Is the component on
which the number of boundaries is to be calculated. For example,
QUARTER finds the difference in quarters between two dates. Valid components
(and acceptable values) are:
- YEAR (1-9999)
- QUARTER (1-4)
- MONTH (1-12)
- WEEK (1-53). This
is affected by the WEEKFIRST setting.
- DAY (of the Month,
1-31)
- HOUR (0-23)
- MINUTE (0-59)
- SECOND (0-59)
Example: Returning the Number of Years Between Two Dates
The following request against
the WF_RETAIL data source calculates employee age when hired:
DEFINE FILE WF_RETAIL
YEARS/I9 = DTDIFF(START_DATE, DATE_OF_BIRTH, YEAR);
END
TABLE FILE WF_RETAIL
PRINT START_DATE DATE_OF_BIRTH YEARS AS 'Hire,Age'
BY EMPLOYEE_NUMBER
WHERE EMPLOYEE_NUMBER CONTAINS 'AA'
ON TABLE SET PAGE NOPAGE
END
The output
is:
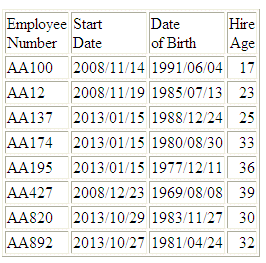
x
DTPART: Returning a Date or Date-Time Component in Integer Format
Given a date in standard date or date-time format and
a component, DTPART returns the component value in integer format.
x
Syntax: How to Return a Date or Date-Time Component in Integer Format
DTPART(date, component)
where:
- date
-
Date or date-time
Is the date in standard date or date-time format.
- component
-
Keyword
Is the component to extract in integer format.
Valid components (and values) are:
- YEAR (1-9999).
- QUARTER (1-4).
- MONTH (1-12).
- WEEK (of the year,
1-53). This is affected by the WEEKFIRST setting.
- DAY (of the Month,
1-31).
- DAY_OF_YEAR (1-366).
- WEEKDAY (day of the
week, 1-7). This is affected by the WEEKFIRST setting.
- HOUR (0-23).
- MINUTE (0-59).
- SECOND (0-59.)
- MILLISECOND (0-999).
- MICROSECOND (0-999999).
Example: Extracting the Quarter Component as an Integer
The following request against
the WF_RETAIL data source extracts the QUARTER component from the
employee start date:
DEFINE FILE WF_RETAIL
QTR/I2 =DTPART(START_DATE, QUARTER);
END
TABLE FILE WF_RETAIL
PRINT START_DATE QTR AS Quarter
BY EMPLOYEE_NUMBER
WHERE EMPLOYEE_NUMBER CONTAINS 'AH'
ON TABLE SET PAGE NOPAGE
END
The output
is:
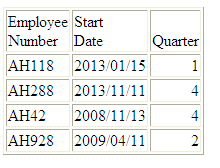
x
DTRUNC: Returning the Start of a Date Period for a Given Date
Given a date or timestamp and a component, DTRUNC returns
the first date within the period specified by that component.
x
Syntax: How to Return the First Date of a Date Period
DTRUNC(date_or_timestamp, date_period)
where:
- date_or_timestamp
-
Date or date-time
Is the date or timestamp of interest.
- date_period
-
Is the period
whose starting date you want to find. Can be one of the following:
- DAY, returns day
of the month (1-31).
- YEAR, returns year
(1-9999).
- MONTH, returns month
(1-12).
- QUARTER, returns
quarter (1-4).
Example: Returning the First Date in a Date Period
In the following request
against the WF_RETAIL data source, DTRUNC returns the first date
of the quarter given the start date of the employee:
DEFINE FILE WF_RETAIL
QTRSTART/YYMD = DTRUNC(START_DATE, QUARTER);
END
TABLE FILE WF_RETAIL
PRINT START_DATE QTRSTART AS 'Start,of Quarter'
BY EMPLOYEE_NUMBER
WHERE EMPLOYEE_NUMBER CONTAINS 'AH'
ON TABLE SET PAGE NOPAGE
END
The output
is:
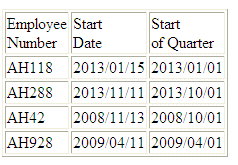
xCHECKPRIVS: Retrieving the Privilege State for the Connected User
Given a privilege code, CHECKPRIVS returns the value
Y, if the connected user has that privilege, or N if the user does
not have the privilege or the privilege does not exist.
Note: You can see your list of general privileges
by clicking the Console (C) button at the top left corner of the
window and selecting My Console/Show My General Privileges.
A user with Server Administrator privileges can also see the list
of general privileges on the Access Control page by right-clicking
a user ID, selecting Properties from the
context menu and clicking the General Privileges tab
on the Properties page.
x
Syntax: How to Retrieve the Privilege State for the Connected User
CHECKPRIVS(privcode, output)
where:
- privcode
-
Is the privilege code for which to retrieve
the status.
- output
-
Alphanumeric
Is
the name of the field that contains the result, or the format of
the output value enclosed in single quotation marks.
Example: Retrieving the Privilege State for the Connected User
The following request retrieves
the privilege state for privilege ADPTP (Configure Data Adapter):
-SET &PRIVSTATE = CHECKPRIVS(ADPTP,'A1');
-TYPE Privilege State is: &PRIVSTATE
The output is:
Privilege State is: Y
xAdding a Value Test to RESTRICT=NOPRINT
Under prior releases, a RESTRICT=NOPRINT DBA restriction
displayed all values or only default values (blank, zero, or MISSING).
This optional extension to RESTRICT=NOPRINT enables you to use
a VALUE=expression clause in the RESTRICT command. The expression
will be evaluated, and the value will display only if the expression
evaluates to true for that value. Any value for which the expression
evaluates to false will be replaced on the output by one of the
default values.
Therefore, a DBA command that includes
the following restriction will only display the true value of SEATS
when COUNTRY has the value 'ENGLAND'. Otherwise, default values are
displayed:
RESTRICT=NOPRINT, NAME=SEATS, VALUE= COUNTRY EQ 'ENGLAND';,$
xUsing a SYNONYM or FOCEXEC for ACCEPT Values in a Master File
The functionality of ACCEPT in a Master File has been
extended. When placed on a FIELD declaration, it can be used to
control the values that show up in a filter (WHERE) dialogue box.
When used with a global amper variable in the Master File, it can
be used to control the values displayed by the Amper Auto-Prompting
facility.
The ACCEPT attribute supports the following
types of operations:
- ACCEPT = value1 OR value2 ...
This
option is used to specify one or more acceptable values.
- ACCEPT = value1 TO value2
This option is used to specify a range of acceptable
values.
- ACCEPT = FIND
This
option is used to validate incoming transaction data against a value
from a FOCUS data source when performing maintenance operations
on another data source. FIND is only supported for FOCUS data sources
and does not apply to OLAP-enabled synonyms. Note also that, in
the Maintain environment, FIND is not supported when developing
a synonym.
- ACCEPT = DECODE
This
option is used to supply pairs of values for auto amper-prompting.
Each pair consists of one value that can be looked up in the data
source and a corresponding value for display.
- ACCEPT = FOCEXEC
This
option is used to retrieve lookup and display field values by running
a FOCEXEC. Each row in the output must include one value for lookup
and a corresponding value for display. These values can be anywhere
in the row, in any order. The FOCEXEC can return other columns as
well.
- ACCEPT = SYNONYM
This
option is used to look up values in another data source and retrieve
a corresponding display value. The lookup field values must exist
in both data sources, although they do not need to have matching
field names. You supply the name of the synonym, the lookup field
name and the display field name.
x
Syntax: How to Use ACCEPT = FOCEXEC in a Master File
ACCEPT=FOCEXEC(lookup_field AS display_field IN lookup_focexec)
where:
- lookup_field
Is the field returned by the FOCEXEC whose value will be
used in the filter (WHERE dialogue) or by the amper autoprompt facility
that will be compared with the field that has the ACCEPT attribute.
- display_field
Is the field returned by the FOCEXEC, whose value will be
displayed for selection in the filter dialogue or amper autoprompt
drop-down list.
- lookup_focexec
Is the name of the FOCEXEC that returns the lookup and display
field values, in any order. This FOCEXEC can return other field
values as well.
x
Syntax: How to Use ACCEPT = SYNONYM in a Master File
ACCEPT=SYNONYM(lookup_field AS display_field IN lookup_synonym)
where:
- lookup_field
Is the field in the lookup_synonym whose value will be used
in the filter (WHERE dialogue) or by the amper autoprompt facility
that will be compared with the field that has the ACCEPT attribute.
- display_field
Is the field in the lookup_synonym, whose value will be displayed
for selection in the filter dialogue or amper autoprompt drop-down
list.
- lookup_synonym
-
Is the name of the synonym that describes the lookup data.
xUsing Multiple Prefix Operators on the Same Measure in SUBTOTAL
You can now reference a field with multiple prefix operators
in a summary command using the prefix operator to differentiate
between the fields with multiple operators.
Using prefix operators on summary lines requires the setting
SET SUMMARYLINES=NEW. This is now the default setting.
xValidating Parameter Values Without Data File Access: REGEX
You can now validate a parameter value without accessing
the data by using the REGEX mask. The REGEX mask specifies a regular
expression to be used as the validation string. A regular expression
is a sequence of special characters and literal characters that
you can combine to form a search pattern.
Many references for regular expressions exist on the web. For
a basic summary, see the section Summary of Regular Expressions in
Chapter 2, Security, of the Server Administration manual.
The syntax for validating a variable using the REGEX mask is
&variable.(|VALIDATE=REGEX,REGEX='regexpression').
where:
- &variable
-
Is the variable to validate.
- regexpression
-
Is the regular expression that specifies the
acceptable values.
For example, the following request validates
a Social Security number in either xxxxxxxxx or xxx-xx-xxxx format:
-REPEAT NEXTFMT FOR &FMTCNT FROM 1 TO 2
-SET &EMPID1=DECODE &FMTCNT(1 '071382660' 2 '818-69-2173');
-SET &EMPID=IF &EMPID1.(|VALIDATE=REGEX,REGEX='^\d{3}\-?\d{2}\-?\d{4}$').Employee ID. CONTAINS '-'
- THEN EDIT(&EMPID1,'999$99$9999') ELSE &EMPID1;
TABLE FILE EMPLOYEE
HEADING
" "
"Testing EMPID = &EMPID1</1"
PRINT EID CSAL
WHERE EID EQ '&EMPID.EVAL'
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
END
-RUN
-NEXTFMT The output is
Testing EMPID = 071382660
EMP_ID CURR_SAL
071382660 $11,000.00
Testing EMPID = 818-69-2173
EMP_ID CURR_SAL
818692173 $27,062.00
The following messages display in case of an error:
(FOC2909) INVALID REGULAR EXPRESSION:
(FOC2910) RESPONSE DOES NOT MATCH THE REGULAR EXPRESSION:
xAdding DBA Restrictions to the Join Condition
When DBA restrictions are applied to a request on a
multi-segment structure, by default the restrictions are added as
WHERE conditions in the report request. When the DBAJOIN parameter
is set ON, DBA restrictions are treated as internal to the file or
segment for which they are specified, and are added to the join
syntax.
This difference is important when the file or segment being restricted
has a parent in the structure and the join is an outer or unique
join.
When restrictions are treated as report filters, lower-level
segment instances that do not satisfy them are omitted from the
report output, along with their host segments. Since host segments
are omitted, the output does not reflect a true outer or unique
join.
When the restrictions are treated as join conditions, lower-level
values from segment instances that do not satisfy them are displayed
as missing values, and the report output displays all host rows.
x
Syntax: How to Add DBA Restrictions to the Join Condition
SET DBAJOIN = {OFF|ON}
where:
-
OFF
-
Treats DBA restrictions as WHERE filters
in the report request. OFF is the default value.
- ON
-
Treats DBA restrictions as join conditions.
Example: Using the DBAJOIN Setting With Relational Tables
The following request creates
two tables, EMPINFOSQL and EDINFOSQL:
TABLE FILE EMPLOYEE
SUM LAST_NAME FIRST_NAME CURR_JOBCODE
BY EMP_ID
ON TABLE HOLD AS EMPINFOSQL FORMAT SQLMSS
END
-RUN
TABLE FILE EDUCFILE
SUM COURSE_CODE COURSE_NAME
BY EMP_ID
ON TABLE HOLD AS EDINFOSQL FORMAT SQLMSS
END
Add the following DBA attributes to
the end of the generated EMPINFOSQL Master File. With the restrictions
listed, USER2 cannot retrieve course codes of 300 or above:
END
DBA=USER1,$
USER=USER2, ACCESS = R, $
FILENAME=EDINFOSQL,$
USER=USER2, ACCESS = R, RESTRICT = VALUE, NAME=SYSTEM, VALUE=COURSE_CODE LT 300;,$
Add the following DBA attributes
to the end of the generated EDINFOSQL Master File:
END
DBA=USER1,DBAFILE=EMPINFOSQL,$
Issue the following request:
SET USER=USER2
SET DBAJOIN=OFF
JOIN LEFT_OUTER EMP_ID IN EMPINFOSQL TO MULTIPLE EMP_ID IN EDINFOSQL AS J1
TABLE FILE EMPINFOSQL
PRINT LAST_NAME FIRST_NAME COURSE_CODE COURSE_NAME
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
GRID=OFF,$
END
On the report
output, all host and child rows with course codes 300 or above have
been omitted, as shown in the following image:

In the generated
SQL the DBA restriction has been added to the WHERE predicate in the
SELECT statement:
SELECT
T1."EID",
T1."LN",
T1."FN",
T2."CC",
T2."CD"
FROM
EMPINFOSQL T1,
EDINFOSQL T2
WHERE
(T2."EID" = T1."EID") AND
(T2."CC" < '300;');
Rerun the request with SET DBAJOIN=ON.
The output now displays all host rows, with missing values substituted
for lower-level segment instances that did not satisfy the DBA restriction,
as shown on the following image:
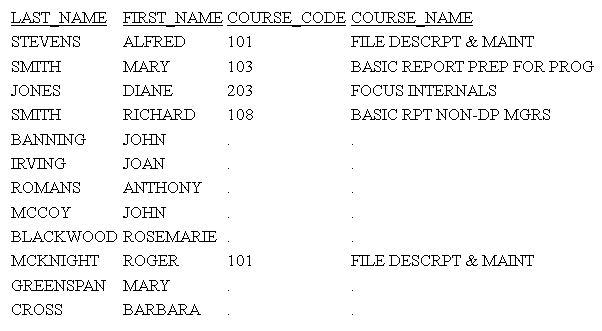
In the generated
SQL, the DBA restriction has been added to the join, and there is
no WHERE predicate:
SELECT
T1."EID",
T1."LN",
T1."FN",
T2."EID",
T2."CC",
T2."CD"
FROM
( EMPINFOSQL T1
LEFT OUTER JOIN EDINFOSQL T2
ON T2."EID" = T1."EID" AND
(T2."CC" < '300;') );
xStoring Localized Metadata in Language Files
Localized column titles and description attributes can
be stored in a Master File using the TITLE_lng and DESC_lng attributes.
However, if you want to centralize localized column titles, descriptions,
and prompts, and apply them to multiple Master Files, you can create
a set of translation files and use the TRANS_FILE attribute in a
Master File to invoke them.
x
Syntax: How to Create and Invoke Metadata Translation Files
Translation File Naming Conventions
The translation
files have names of the following form:
prefix lng.lng
where:
- prefix
-
Is a group of characters prepended to each
related translation file.
- lng
-
Is a language code.
For example, if the common prefix is dt, the
French translation file would be named dtfre.lng, and the English
translation file would be named dteng.lng.
Translation File Contents
The prefixeng.lng
file must contain any title, description, and prompt values that
you want translated as they appear in the Master File, whether they
are in English or another language:
- Copy each attribute
value from the Master File that you want translated into the default
(eng) translation file, and assign it an index number. The index
numbers do not need to be consecutive or in order. For example:
39 = Product,Category
- Add the translations
of those attribute values to the translation files for the other languages
in which you want to display the metadata. Assign the same index
number to the translations. For example, in the French translation
file:
39 = Produit,Catégorie
Identifying the Translation Files to Use For a Master File
To specify that a Master File should
use a particular set of translation files, identify the common prefix
in the FILE declaration of the Master File:
FILENAME=filename, TRANS_FILE=[path]/prefix, ...
where:
- filename
-
Is the name specified in the FILE= attribute.
- path
-
Is the information needed for locating
the set of translation files. It can be a full path or an app reference.
If there is one set of translation files with the prefix being used and
it is on the app path, this can be omitted.
- prefix
-
Is the common prefix for the set of translation
files.
Invoking the Translation Files for a Request
- Make sure the server
is using a code page that supports the languages to be used.
- Set the LANGUAGE
parameter to the language in which the metadata should be displayed.
- Run the request.
Example: Using Translation Files
The following request uses the WF_RETAIL_LITE
data source:
TABLE FILE WF_RETAIL
SUM REVENUE_US
BY PRODUCT_CATEGORY
BY PRODUCT_SUBCATEG
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE = TITLE, FONT='Trebuchet MS', $
ENDSTYLE
END
The output
is:
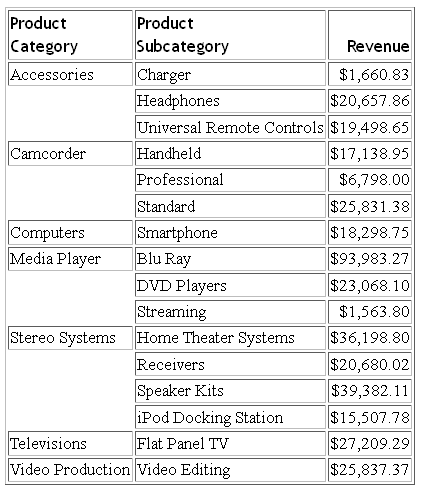
The Master
File contains the following TRANS_FILE attribute:
FILENAME=WF_RETAIL_LITE, TRANS_FILE=_EDAHOME/NLS/dt, ...
The TRANS_FILE attribute points
to files that start with the characters dt that are in the
NLS folder under the EDAHOME directory. The following sample shows
some of the contents of the default translation file, dteng.lng:
1 = Age
2 = Age Range
3 = Age Group
6 = Gender
9 = Discount,Rate
10 = Discount,Price,Multiplier
15 = Country
17 = State
19 = City
31 = Customer,Income Range
32 = Customer,Income Subrange
33 = Households
34 = Number of,Earners
35 = Household,Size
36 = Industry
38 = Occupation
39 = Product,Category
40 = Product,Subcategory
41 = Brand Type
The text assigned to each
number can be found in one of the Master Files associated with the
WF_RETAIL_LITE Master File. WF_RETAIL_LITE is a cluster Master File
that references fact and dimension Master Files to create a star
schema.
The following
sample shows the corresponding contents of the French translation
file, dtfre.lng:
1 = Age
2 = Tranche d'âge
3 = Groupe d'âge
6 = Sexe
9 = Remise,Taux
10 = Remise,Prix,Multiplicateur
15 = Pays
17 = Département
19 = Ville
31 = Client,Tranche de revenus
32 = Client,Sous-tranche de revenus
33 = Ménages
34 = Nombre de,Salariés
35 = Ménage,Taille
36 = Secteur d'activité
38 = Profession
39 = Produit,Catégorie
40 = Produit,Sous-catégorie
41 = Type de marque
When the language
is set to French, any text to be displayed that is an exact match
to an index number in the dteng.lng file will be substituted with
the text for the same index number in the dtfre.lng file.
The following version of the
request adds the SET LANG=FRE command. The server code page supports
English and French:
SET LANG = FRE
TABLE FILE WF_RETAIL
SUM REVENUE_US
BY PRODUCT_CATEGORY
BY PRODUCT_SUBCATEG
ON TABLE SET PAGE NOPAGE
ON TABLE SET STYLE *
TYPE = TITLE, FONT='Trebuchet MS', $
ENDSTYLE
END
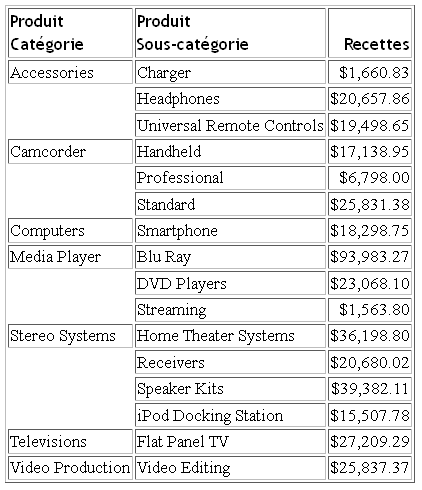
The output
has translated column titles:
xCustomizing the Amper Auto-Prompting Facility
The
option to select different launch page templates can be set in the
WebFOCUS Administration Console using the Parameter Prompting selection
under Client Settings. The setting to use to select the launch page
template depends upon the type of Auto-prompt implementation you
select in the WF_describe_type setting.
If you set WF_describe_type to HTML, which is the default HTML-based implementation,
then you must assign the launch page template to the WF_describe_html setting.
If you set WF_describe_type to XSLT, which is the XSL-based implementation,
then you must assign the launch page template to the IBIF_describe_xsl
setting.
You can also enter the name of the desired launch page template
in a FOCEXEC.
For an HTML-based Auto-prompt implementation, use the following
code:
<describe_html>template</describe_html>
where:
- template
Is set to one of the following launch page template values:
- autoprompt_top. Displays the parameters horizontally
at the top of the page and is the default template value.
- autoprompt_top_checked. Is the same as autoprompt_top,
but the Run in a new window check box is preselected.
For an XSL-based Auto-prompt implementation, use the following
code:
<describe_xsl>template</describe_xsl>
where:
- template
Is set to one of the following launch page template values:
- autoprompt_top. Displays the parameters horizontally
at the top of the page and is the default template value.
- autoprompt_top_checked. Is the same as autoprompt_top,
but the Run in a new window check box is preselected.
- autoprompt. Displays the parameters vertically at the
left side of the page.
- autoprompt_checked. Is the same as autoprompt, but the
Run in a new window check box is preselected.
- autoprompt_simple. Is the basic input form.