-
Right-click
a synonym name and select Quick ETL Copy.
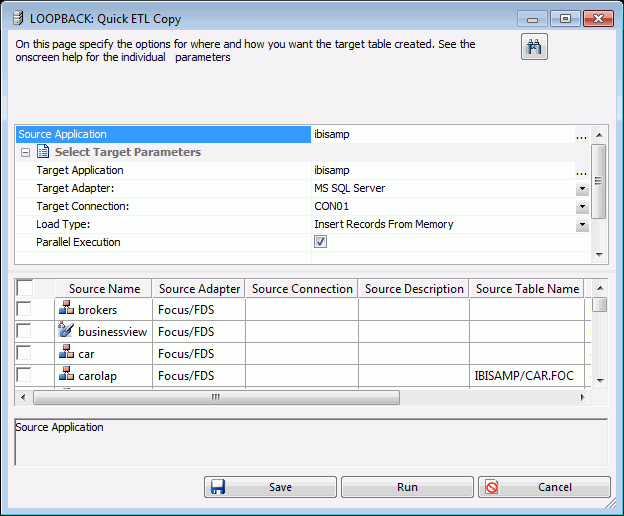
The Quick ETL Copy dialog box opens, as shown in the following image.
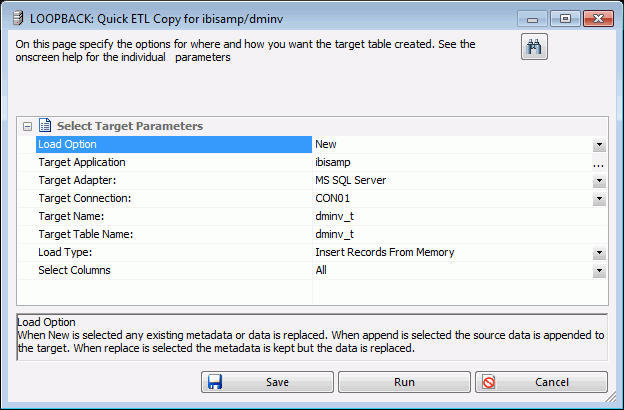
- Load Option
-
The following options are available:
- New. Any existing metadata or data is replaced.
- Append Existing Data (Keep Metadata). The source data is appended to the target.
- Replace Existing Data (Keep Metadata). The metadata is kept but the data is replaced.
- Target Application
-
The application directory where the target tables and generated flow will be stored.
- Target Adapter
-
Use the drop-down menu to select a database configured as an adapter.
- Target Connection
-
Use the drop-down menu to select a connection for the selected adapter.
- Target Name
-
The synonym name for the target table. By default, this is the same name as the source table unless the Application directory is the same, in which case _t is added to the name.
- Target Table Name
-
The name of the target table name in the database. By default, this is the same name as the source table, unless the Adapter and Connection are the same as the source in which case _t is added to the name.
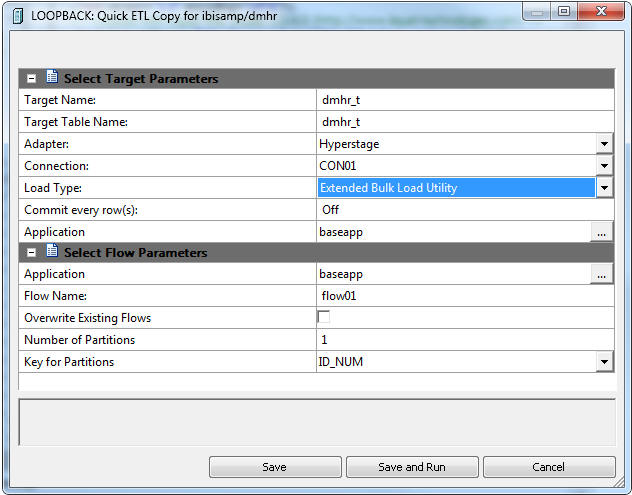
- Load Type
-
Specifies the method DataMigrator uses to load data. Select Insert Records from Memory, Load with Aggregations, Bulk Load Utility via Disk File, or Extended Bulk Load Utility if the database supports any of these options.
- Number of Partition
-
The number of parallel flows to run simultaneously for parallel processing. This option is only available if the source table has one or more numeric columns as key.
- Key for Partitions
-
The field to use to partition the table. This option is only available if the source table has one or more numeric columns as key.
- Retain multisegment/multidimension structure
-
This option is only available when the source is a cluster join for a Star Schema. It is useful when copying to Hyperstage or other column oriented database. Although a single table is created from the joined structure, the synonym retains the structure of the source so that existing procedures that reference the table can continue to be used.
- Select Columns
-
The options are All or manual. If manual is selected, an additional dialog box opens which allows you to select which columns are copied.
The dialog box that opens allows you to select which columns are copied. You can drag and drop fields from the Segments/Fields pane on the left to specific folders in the Columns/Filters pane on the right. The options are:
- Columns. Includes the Segments/Fields in the target table.
- Order by. Sorts the target.
- Filters. Create a filter using the selected field.
- Retain auxiliary metadata
-
In addition to copying the actual data, metadata elements from the source synonym are copied to the new synonym for the target. These include Defined fields, Filters, and Variables.
When Bulk Load Utility via Disk File or Extended Bulk Load is used, additional parameters are available. For more information, see Load Options.
-
In the Target
Application box, select the application directory where to save
the flow by either typing in the location of the directory, or clicking
the ellipses and manually selecting it from the Select Application
dialog box.
If Select Columns was set to Manual, select the check boxes of the columns you want to copy.
- Click Save or Run. Two flows will be created, a process flow with the name you specified, and a data flow with the name followed by the table name. For example, flow01_dmhr. The process flow calls the data flow to copy the table.