In this section: How to: Reference: |
The NEXT command selects and reads segment instances
from a data source. You can use NEXT to read an entire set of records
at a time, or just a single segment instance. You can select segments
by field value or sequentially.
You specify a path running from an anchor segment to a target
segment. NEXT reads all the fields from the anchor through the target,
and (if the anchor segment is not the root) all the keys of the
ancestor segments of the anchor. It copies what it has read to the
stack that you specify or, if you omit a stack name, to the Current
Area.
If the anchor segment is not the root, you must establish a current
instance in each of the ancestor segments of the anchor. This enables
NEXT to navigate from the root to the current instance of the anchor
segment.
In each segment that it reads, NEXT works its way forward through
the segment chain. When no more records are available, the NONEXT
condition arises and no more records are retrieved unless the procedure
issues a REPOSITION command. REPOSITION causes a reposition to just
prior to the beginning of the segment chain. If you are familiar
with the SQL language, the NEXT command acts as a combination of
the SQL commands SELECT and FETCH, and allows you to use the structure
of the data source to your advantage when retrieving data.
x
Syntax: How to Use the NEXT Command
The syntax
of the NEXT command is
[FOR {int|ALL}] NEXT path [INTO stack[(row)]][WHERE where_expression1
[AND where_expression2 ...]] [;]where:
- FOR
Is a prefix that is used with int or ALL to specify
how many data source records are to be retrieved. If FOR is not
specified, NEXT works like FOR 1 and the next record is retrieved.
If the FOR phrase is used, the INTO phrase must also be used.
- int
Is an integer constant or variable that specifies the number
of data source records that are retrieved from the data source.
Retrieval starts at the current position in the data source.
- ALL
Specifies that starting at the current data source position,
all data source segments referred to in the field list are examined.
- path
Identifies the path to be read from the data source. To identify
a path, specify its anchor and target segments. If the path contains
only one segment, the anchor and target are identical, simply specify
the segment once. (For paths with multiple segments, if you wish
to make the code clearer to readers, you can also specify segments
between the anchor and target.)
To specify a segment, provide
the name of the segment or of a field within the segment.
- INTO
Is used with a stack name to specify the name of the stack
into which the data source records are copied.
- stack
Is the name of the stack that the data source values are
placed into. Only one stack can be specified.
- row
Is a subscript that specifies in which row of the stack the
data source values are placed. If no subscript is provided, the
data is placed in the stack starting with the first row.
- where_expression1, where_expression2
Is any valid NEXT WHERE expression. You can use any valid
relational expression, described in Relational Expressions.
NEXT can also use some enhanced screening conditions not available
in other situations. For more information, see Using Selection Logic to Retrieve Rows.
- ;
Terminates the command. Although the semicolon is optional,
it is recommended that you include it to allow for flexible syntax
and better processing. For more information about the benefits of
including the semicolon, see Terminating Command Syntax.
x
Reference: Usage Notes for NEXT
- If an INTO stack
is specified, and that stack already exists, new rows are added
starting at the row specified. If no stack row number is specified
then data is added starting at the first row. In either case, it
is possible that some existing rows may be written over. If a NEXT
command causes only some of the rows in a stack to be overwritten,
the rest of the stack remains intact. If the subscript provided
on the INTO stack is past the end of the existing stack, the intervening
rows are initialized to spaces, zeroes, or nulls (missing values)
as appropriate. If the new stack overwrites some of the rows of
the existing stack, only those rows are affected. The rest of the
stack remains intact.
- If no FOR prefix
is used and no stack name is supplied, the values retrieved by the NEXT
command go into the Current Area.
x
Reference: Commands Related to NEXT
-
REPOSITION. Changes
the data source position to be at the beginning of the chain.
-
MATCH. Searches
the entire segment for a matching field value. It retrieves an exact
match in the data source.
xCopying Data Between Data Sources
You can use the NEXT command to copy data between data
sources. It is helpful to copy data between data sources when transaction
data is gathered by one application and must be stored for use by
another application. It is also helpful when the transaction data
is to be applied to the data source at a later time or in a batch
environment.
Example: Copying Data to the Movies Data Source
For
example, assume that you want to copy data from a fixed-format data
source named FilmData into a FOCUS data source named Movies. You
describe FilmData using the following Master File:
FILENAME=FILMDATA, SUFFIX=FIX
SEGNAME=MOVINFO, SEGTYPE=S0
FIELDNAME=MOVIECODE, ALIAS=MCOD, USAGE=A6, ACTUAL=A6,$
FIELDNAME=TITLE, ALIAS=MTL, USAGE=A39, ACTUAL=A39,$
FIELDNAME=CATEGORY, ALIAS=CLASS, USAGE=A8, ACTUAL=A8,$
FIELDNAME=DIRECTOR, ALIAS=DIR, USAGE=A17, ACTUAL=A17,$
FIELDNAME=RATING, ALIAS=RTG, USAGE=A4, ACTUAL=A4,$
FIELDNAME=RELDATE, ALIAS=RDAT, USAGE=YMD, ACTUAL=A6,$
FIELDNAME=WHOLESALEPR, ALIAS=WPRC, USAGE=F6.2, ACTUAL=A6,$
FIELDNAME=LISTPR, ALIAS=LPRC, USAGE=F6.2, ACTUAL=A6,$
FIELDNAME=COPIES, ALIAS=NOC, USAGE=I3, ACTUAL=A3,$
The
fields in FilmData have been named identically to those in Movies
to establish the correspondence between them in the INCLUDE command
that writes the data to Movies.
You can read FilmData into
Movies using the following procedure:
MAINTAIN FILE Movies AND FilmData
FOR ALL NEXT FilmData.MovieCode INTO FilmStack;
FOR ALL INCLUDE Movies.MovieCode FROM FilmStack;
END
All field names in the procedure are qualified
to distinguish between identically-named fields in the input data
source (FilmData) and the output data source (Movies).
xLoading Multi-Path Transaction Data
When you wish to load data from a transaction data source
into multiple paths of a data source, you should process each path
independently. Use one pair of NEXT and INCLUDE commands per path.
For example, assume that you have a transaction data source named
TranFile whose structure is identical to that of the VideoTrk data
source.
If you wish to load the transaction data from both paths of TranFile
into both paths of VideoTrk, you could use the following procedure:
MAINTAIN FILES TranFile AND VideoTrk
FOR ALL NEXT TranFile.CustID TranFile.ProdCode INTO ProdStack;
REPOSITION CustID;
FOR ALL NEXT TranFile.CustID TranFile.MovieCode INTO MovieStack;
FOR ALL INCLUDE VideoTrk.CustID VideoTrk.ProdCode FROM ProdStack;
FOR ALL INCLUDE VideoTrk.CustID VideoTrk.MovieCode FROM MovieStack;
END
Alternatively, if you choose to store each path of transaction
data in a separate single-segment transaction data source, the same
principles apply. For example, if the two paths of TranFile are
stored separately in transaction data sources TranProd and TranMove,
the previous procedure would change as highlighted below:
MAINTAIN FILES TranProd AND TranMove AND VideoTrk
FOR ALL NEXT TranProd.CustID INTO ProdStack;
FOR ALL NEXT TranMove.CustID
INTO MovieStack;
FOR ALL INCLUDE VideoTrk.CustID VideoTrk.ProdCode FROM ProdStack;
FOR ALL INCLUDE VideoTrk.CustID VideoTrk.MovieCode FROM MovieStack;
END
xRetrieving Multiple Rows: The FOR Phrase
The FOR phrase is used to specify the number of data
source records that are to be retrieved. As an example, if FOR 10
is used, ten records are retrieved. A subsequent FOR 10 retrieves
the next ten records starting from the last position. If an attempt
to retrieve ten records only returns seven because the end of the
chain is reached, the command retrieves seven records, and the ON
NONEXT condition is raised.
The following retrieves the next ten instances of the EmpInfo
segment and places them into Stackemp:
FOR 10 NEXT Emp_ID INTO Stackemp;
xUsing Selection Logic to Retrieve Rows
When you are retrieving rows using the NEXT command,
you have the option to restrict the rows you retrieve using the
WHERE clause. The syntax for this option is
WHERE operand1 comparison_op1 operand2
[AND operand3 comparison_op1 operand4 ...]
where:
- operand1, operand2, operand3, operand4, ...
Are operands. In each NEXT WHERE expression, one operand
must be a data source field, and one must be a valid Maintain expression
that does not refer to a data source field.
For more information
about Maintain expressions, see Expressions Reference.
- comparison_op1, comparison_op2, ...
Can be any of the comparison operators listed in Logical Operators or
any of the comparison operators listed in Comparison Operators.
Some comparison operators may be listed in both places. This means
that they can be used in a WHERE clause in an enhanced way.
The following example retrieves every instance of the EmpInfo
segment that has a department value of MIS:
FOR ALL NEXT Emp_ID INTO EmpStack WHERE Department EQ 'MIS';
Literals can be enclosed in either single (') or double (") quotation
marks. For example, the following produces exactly the same results
as the last example:
FOR ALL NEXT Emp_ID INTO EmpStack WHERE Department EQ "MIS";
The ability to use either single or double quotation marks provides
the added flexibility of being able to use either single or double
quotation marks in text. For example:
NEXT Emp_ID WHERE Last_Name EQ "O'HARA";
NEXT Product WHERE Descr CONTAINS '"TEST"';
This example starts at the beginning of the segment chain and
searches for all employees that are in the MIS department. All retrieved
segment instances are copied into a stack:
REPOSITION Emp_ID;
FOR ALL NEXT Emp_ID INTO Misdept WHERE Department EQ 'MIS';
After FOR ALL NEXT is processed, you are positioned at the end
of the segment chain. Therefore, before issuing an additional NEXT
command on the same segment chain, you should issue a REPOSITION
command to be positioned prior to the first instance in the segment
chain.
x
Reference: Comparison Operators
- IS, EQ, NE, IS_NOT
-
Select data source values using wildcard characters (you
embed the wildcards in a character constant in the non-data source
operand). You can use dollar sign wildcards ($) throughout the constant
to signify that any character is acceptable in the corresponding
position of the data source value.
If you wish to allow any
value of any length at the end of the data source value, you can
combine a dollar sign wildcard with an asterisk ($*) at the end
of the constant.
For example:
WHERE ZipCode IS '112$$'
- CONTAINS, OMITS
-
Select data source values that contain or omit a character
string stored in a variable.
For example, the following returns
all data where the word BANK is part of the bank name:
COMPUTE name/A4 = 'BANK';
FOR ALL NEXT bank_code
bank_name into stackname
WHERE bank_name CONTAINS
name;
The following returns all data where the bank
name does not include the word BANK:
COMPUTE name/A4 = 'BANK';
FOR ALL NEXT bank_code
bank_name into stackname
WHERE bank_name OMITS name;
- EXCEEDS
-
Selects data source values that are greater than a numeric
value.
For example:
WHERE TOTAL Curr_sal EXCEEDS 110000
- IN (list), NOT_IN (list)
-
Select data source values that are in or not in a list. IN
and NOT_IN can be used with all data types.
For example, the
following returns all data where the bank name is not in the list:
FOR ALL NEXT emp_id bank_name INTO stackname
WHERE bank_name NOT_IN
('ASSOCIATED BANK', CITIBANK) - EQ_MASK, NE_MASK
-
Select data source values that match or do not match a mask.
Use
the $ sign to replace each letter in the value. Masks can only be
used with alphanumeric data. The masked value may be hard coded
or a variable.
For example, the following returns all data
where the bank code starts with AAA and has any character at the
end:
COMPUTE code/A4='AAA$';
FOR ALL NEXT bank_name
INTO stackname
WHERE bank_code EQ_Mask
code;
The following returns all data where the bank
code does not match the mask:
COMPUTE code/A4='AAA$';
FOR ALL NEXT bank_name
INTO Stackname
WHERE bank_code NE_Mask code;
x
NEXT can also be used in conjunction with the MATCH
command. This example issues a MATCH for employee ID. If there is
not a match, a message is displayed. If there is a match, all the
instances of the child segment for that employee are retrieved and
placed in the stack Stackemp. The NEXT command can be coded as part
of an ON MATCH condition, but it is not required, as the NEXT will
only retrieve data based on the current position of higher level
segments.
MATCH Emp_ID
ON NOMATCH BEGIN
TYPE "The employee ID is not in the data source.";
GOTO Getmore;
ENDBEGIN
FOR ALL NEXT Dat_Inc INTO Stackemp;
xUsing NEXT for Data Source Navigation: Overview
The segments that NEXT operates on are determined by
the fields mentioned in the NEXT command. The list of fields is
used to determine the anchor segment (the segment closest to the
root) and the target segment (the segment furthest from the root).
Every segment starting with the anchor and ending with the target
make up the scope of the NEXT command, including segments not mentioned
in the NEXT command. Both the target and the anchor must be in one
data source path.
NEXT does not retrieve outside the scope of the anchor and target
segment. All segments not referenced remain constant, which is why
NEXT can be used as a get next within parent (GNP).
As an example, look at a partial view of the Employee data source:
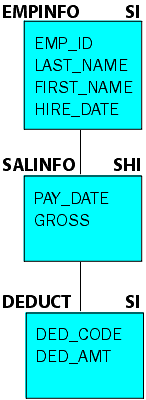
If a NEXT command has SalInfo as the anchor segment and the target
is the Deduct segment, it also needs to retrieve data for the EmpInfo
segment, which is the parent of the SalInfo segment based on its
current position. The position for the EmpInfo segment can be established
by either a prior MATCH or NEXT command. If no position has been
established for the EmpInfo segment, an error occurs.
You can use the NEXT command for:
xData Source Navigation: Using NEXT With One Segment
If a NEXT references only one segment and has no WHERE
phrase or FOR prefix, it always moves forward one instance within
that segment. If the segment is not the root, all parent segments
must have a position in the data source and only those instances descending
from those parents are examined and potentially retrieved. The NEXT
command starts at the current position within the segment, and each
time the command is encountered, it moves forward one instance.
If a prior position has not been established within the segment
(no prior NEXT, MATCH, or REPOSITION command has been issued), the NEXT
retrieves the first instance.
The following command references the root segment, so there is
no parent segment in which to have a position:
NEXT Emp_ID;
The following command refers to a child segment, so the parents
to this segment must already have a position and that position does
not change during the NEXT operation:
NEXT Pay_Date;
If the NEXT command uses the FOR prefix, it works the same as
described above, but rather than moving forward only one data source
instance, it moves forward as many rows as the FOR specifies. The
following retrieves the next three instances of the EmpInfo segment:
FOR 3 NEXT Emp_ID INTO Stemp;
If a FOR prefix is used, an INTO stack must be specified. However,
an INTO stack can be specified without the FOR prefix.
If a WHERE phrase is specified and there is no FOR prefix, the
NEXT moves forward as many times as necessary to retrieve one row
that satisfies the selection criteria specified in the WHERE phrase.
The following retrieves the next employee in the MIS department:
NEXT Emp_ID WHERE Department EQ 'MIS';
If the NEXT command does not have an INTO stack name, the output
of the NEXT (the value of all of the fields in the segment instance)
goes into the Current Area. If an INTO stack is specified, the output
goes into the stack named in the command. If more than one row is
retrieved by using a FOR prefix, the number of rows specified in
the FOR are placed in the stack. If the INTO stack specifies a row
number (for example, INTO Mystack(10)), then the rows are added
to the stack starting with that row number. If the INTO stack does
not specify a row number, the rows are added to the stack starting
at the first row.
The following retrieves all of the fields from the next instance
in the segment that Emp_ID is in and places the output into the
first row of the Stemp stack:
NEXT Emp_ID INTO Stemp;
If the NEXT command has both a WHERE phrase and a FOR prefix,
it moves forward as many times as necessary to retrieve the number
of rows specified in the FOR phrase that satisfies the selection
criteria specified in the WHERE phrase. The following retrieves
the next three employees in the MIS department and places the output
into the stack called Stemp:
FOR 3 NEXT Emp_ID INTO Stemp WHERE Department EQ 'MIS';
If there were not as many rows retrieved as you specified in
the FOR prefix, you can determine how many rows were actually retrieved
by checking the FocCount variable of the target stack.
xData Source Navigation: Using NEXT With Multiple Segments
If a NEXT command references more than one segment,
each time the command is executed it moves forward within the target
(the lowest level child segment). Once the target no longer has
any more instances, the next NEXT moves forward on the parent of
the target and repositions itself at the beginning of the chain
of the child. In the following example, the REPOSITION command changes
the position of EmpInfo to the beginning of the data source (EmpInfo
is in the root). The first NEXT command finds the first instance
of both segments. When the second NEXT is executed, what happens
depends on whether there is another instance of the SalInfo segment,
because the NEXT command does not retrieve short path instances
(that is, it does not retrieve path instances that are missing descendant
segments). If there is another instance, the second NEXT moves forward
one instance in the SalInfo segment. If there is only one instance
in the SalInfo for the employee retrieved in the first NEXT, the
second NEXT moves forward one instance in the EmpInfo segment. When
this happens, the SalInfo segment is positioned at the beginning
of the chain and the first SalInfo instance is retrieved. If there
is no instance of SalInfo, the NEXT command retrieves the next record
that has a SalInfo segment instance.
REPOSITION Emp_ID;
NEXT Emp_ID Pay_Date;
NEXT Emp_ID Pay_Date;
When there is a possibility of short paths, and the intention
is to retrieve the data from the parent even if there is no data
for the child, NEXT should be used on one segment at a time, as
described in Data Source Navigation: Using NEXT Following NEXT or MATCH. If a NEXT
command uses the FOR n prefix, it works the same as described
above, but rather than moving forward only one data source instance,
it moves forward as many records as are required to retrieve the
number specified in the FOR prefix.
For instance, the following command retrieves the next five instances
of the EmpInfo and SalInfo segments and places the output into the
Stemp stack. The five records may or may not all have the same EmpInfo
segment:
FOR 5 NEXT Emp_ID Dat_Inc INTO Stemp;
If the data source is populated as follows,
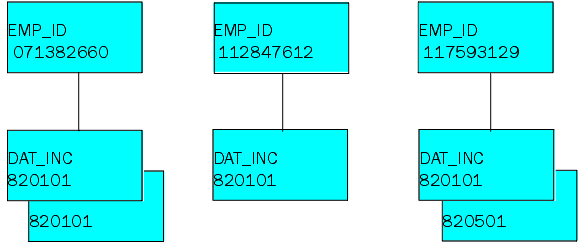
all of the fields from the following segment instances are added
to the stack:
- EMP_ID 071382660,
DAT_INC 820101
- EMP_ID 071382660,
DAT_INC 810101
- EMP_ID 112847612,
DAT_INC 820101
- EMP_ID 117593129,
DAT_INC 820601
- EMP_ID 117593129,
DAT_INC 820501
If a WHERE phrase is specified, the NEXT moves forward as many
times as necessary to retrieve one record that satisfies the selection
criteria specified in the WHERE phrase. For example, the following
retrieves the next record where the child segment has the field Gross
greater than 1,000:
NEXT Emp_ID Pay_Date WHERE Gross GT 1000;
If both a WHERE phrase and a FOR prefix are specified, the NEXT
moves forward as many times as necessary to retrieve the number
specified in the FOR prefix that satisfies the selection criteria
specified in the WHERE phrase. For instance, the following retrieves
all of the records where the Gross field is greater than 1,000.
As stated above, if more than one segment is mentioned and there
is a FOR prefix, the data retrieved may come from more than one
employee:
FOR ALL NEXT Emp_ID Pay_Date INTO Stemp WHERE Gross GT 1000;
If the NEXT command does not have an INTO stack name provided,
the output of the NEXT is copied into the Current Area. If an INTO
stack is specified, the output is copied into the stack named in
the command. The number of records retrieved is the number that
is placed in the stack. If the INTO stack specifies a row number
(for example, INTO Mystack(10)) then the records are added to the
stack starting at the row number. If the INTO stack does not specify
a row number, the rows are added to the stack starting with the
first row in the stack. If data already exists in any of the rows,
those rows are cleared and replaced with the new values.
If the NEXT command can potentially retrieve more than one record
(the FOR prefix is used), an INTO stack must be specified. If no
stack is provided, an error message is displayed and the procedure
is terminated.
xData Source Navigation: Using NEXT Following NEXT or MATCH
In order to use NEXT through several segments, specify
all the segments in one NEXT command or use several NEXT commands.
If all of the segments are placed into one NEXT command, there is
no way to know when data is retrieved from a parent segment and
when it is retrieved from a child. To have control over when each
segment is retrieved, each segment should have a NEXT command of
its own. In this way, the first NEXT establishes the position for
the second NEXT.
A NEXT command following a MATCH command works in a similar way.
The first command (MATCH) establishes the data source position.
In the following example, the REPOSITION command places the position
in the EmpInfo segment and all of its children to the beginning
of the chain. Both NEXT commands move forward to the first instance
in the appropriate segment:
REPOSITION Emp_ID;
NEXT Emp_ID;
NEXT Pay_Date;
If one of the NEXT commands uses the FOR prefix, it works the
same as described above, but rather than moving forward only one
segment instance, NEXT moves forward however many records the FOR
specifies. For example, the following retrieves the first instance
in the EmpInfo segment and the next three instances of the SalInfo
segment. All three records are for only one employee because the
first NEXT establishes the position:
REPOSITION Emp_ID;
NEXT Emp_ID;
FOR 3 NEXT Pay_Date INTO Stemp;
After this code is executed, the stack contains data from the
following segments:
- Emp_ID instance
1 and Pay_Date instance 1
- Emp_ID instance
1 and Pay_Date instance 2
- Emp_ID instance
1 and Pay_Date instance 3
Every NEXT command that uses a FOR prefix does so independent
of any other NEXT command. If there are two NEXT commands, the first
executes. When it is complete, the position is the last instance
retrieved. The second NEXT command then executes and retrieves data
from within the parent established by the first NEXT. In the following
example, the first NEXT retrieves the first two instances from the
EmpInfo segment and places the instances into the stack. The second
NEXT retrieves the next three instances of the SalInfo segment.
Note its parent instance is the second EmpInfo segment instance.
The stack variable FocCount indicates the number of rows currently
in the stack. The prefix Stemp is needed to indicate the stack.
STACK CLEAR Stemp;
REPOSITION Emp_ID;
FOR 2 NEXT Emp_ID INTO Stemp(1);
FOR 3 NEXT Pay_Date INTO Stemp(Stemp.FocCount);
The stack contains data from the following segments after the
first NEXT is executed:
- Emp_ID instance
1
- Emp_ID instance
2
The stack contains data from the following segments after the
second NEXT is executed:
- Emp_ID instance
1
- Emp_ID instance
2 and Pay_Date instance 1
- Emp_ID instance
2 and Pay_Date instance 2
- Emp_ID instance
2 and Pay_Date instance 3
The row in the INTO stack that the output is placed in is specified
by supplying the row number after the stack name. When two NEXT
commands are used in a row for the same stack, care must be taken
to ensure that data is written to the appropriate row in the stack. If
a stack row number is not specified for the second NEXT command,
data is placed into the last row written to by the first NEXT, and
existing data is overwritten. In order to place data in a different
row, a row number or an expression to calculate the row number can
be used. For example, the second NEXT command specifies the row
after the last row by adding one to the variable FocCount:
FOR 2 NEXT Emp_ID INTO Stemp(1);
FOR 3 NEXT Pay_Date INTO Stemp(Stemp.FocCount+1);
The stack now appears as follows. Notice that there is a new
row 2:
- Emp_ID instance
1
- Emp_ID instance
2
- Emp_ID instance
2 and Pay_Date instance 1
- Emp_ID instance
2 and Pay_Date instance 2
- Emp_ID instance
2 and Pay_Date instance 3
If a WHERE phrase is specified, the NEXT moves forward as many
times as necessary to retrieve one record that satisfies the selection
criteria specified in the WHERE phrase. For instance, the following
retrieves the next record where the Gross field of the child segment
is greater than 1,000. Like the previous example, the data retrieved
is only for the employee that the first NEXT retrieves:
NEXT Emp_ID;
NEXT Pay_Date WHERE Gross GT 1000;
If both a FOR prefix and a WHERE phrase are specified, the NEXT
moves forward as many times as necessary to retrieve the number
of records specified in the FOR prefix that satisfy the selection
criteria specified in the WHERE phrase.
For example, the following syntax retrieves the next three records
where the Gross field of the child segment is greater than 1,000.
As above, the data retrieved is only for the employee that the first
NEXT retrieves:
NEXT Emp_ID;
FOR 3 NEXT Pay_Date INTO Stemp WHERE Gross GT 1000;
x
Maintain allows separate segments to be joined in a
one-to-one relation (among other ways). Unique segments are indicated
by specifying a SEGTYPE of U, KU or DKU in the Master File, or by
issuing a JOIN command. In a NEXT command, you retrieve a unique
segment by specifying a field from the segment in the field list
of the command. You cannot specify the unique segment as an anchor
segment.
If an attempt is made to retrieve data from a unique segment
and the segment does not exist, the fields are treated as if they
are fields in the parent segment. This means that the returned data
is spaces, zeroes, and/or nulls (missing values), depending on how
the segment is defined. In addition, the answer set contains as
many rows as the parent of the unique segment. If an UPDATE or a
DELETE command subsequently uses the data in the stack and the unique
segment does not exist, it is not an error, because unique segments are
treated as if the fields are fields in the parent. If an INCLUDE
is issued, the data source is not updated.