Describing a Single Segment
In a segment description, you can describe key fields,
sort order, and segment relationships. The number of segments cannot
exceed 64 in a FOCUS data source, or 512 in an XFOCUS data source.
Non-FOCUS data sources can have up to 1024 segments. and FOCUS data
sources can participate in join structures
that consist of up to 1024 segments.
Using an indexed view reduces the maximum number of segments
plus indexes to 191 for the structure being used. If AUTOINDEX is
ON, you may be using an indexed view without specifically asking
for one.
You can code LOCATION segments in a Master File to expand the
file size by pointing to another physical file location.
You can also create a field to timestamp changes to a segment
using AUTODATE.
Three additional segment attributes that describe joins between
FOCUS segments, CRFILE, CRKEY, and CRSEGNAME, are described in Defining a Join in a Master File.
xDescribing Keys, Sort Order, and Segment Relationships: SEGTYPE
FOCUS data sources use the SEGTYPE attribute to describe
segment key fields and sort order, as well as the relationship of
the segment to its parent.
The SEGTYPE attribute is also used with SUFFIX=FIX data sources
to indicate a logical key sequence for that data source. SEGTYPE
is discussed in Describing a Group of Fields.
x
Syntax: How to Describe a Segment
The
syntax of the SEGTYPE attribute when used for a FOCUS data source
is
SEGTYPE = segtype
Valid values are:
- SH[n]
Indicates that the segment instances are sorted from highest
to lowest value, based on the value of the first n fields
in the segment. n can be any number from 1 to 99. If you
do not specify it, it defaults to 1.
- S[n]
Indicates that the segment instances are sorted from lowest
value to highest, based on the value of the first n fields
in the segment. n can be any number from 1 to 255. If you
do not specify it, it defaults to 1.
- S0
Indicates that the segment has no key field and is therefore
not sorted. New instances are added to the end of the segment chain.
Any search starts at the current position.
S0 segments are
often used to store text for applications where the text needs to be
retrieved in the order entered, and the application does not need
to search for particular instances.
- (blank)
Indicates that the segment has no
key field, and is therefore not sorted. New instances are added
to the end of the segment chain. Any search starts at the beginning of
the segment chain.
SEGTYPE = blank
segments are often used in situations where there are very few segment
instances, and the information stored in the segment does not include
a field that can serve as a key.
Note that a root segment
cannot be a SEGTYPE blank segment.
- U
Indicates that the segment is unique, with a one-to-one relationship
to its parent. Note that a unique segment described with a SEGTYPE
of U cannot have any children.
- KM
Indicates that this is a cross-referenced segment joined
to the data source using a static join defined in the Master File
and has a one-to-many relationship to the host segment. Joins defined
in the Master File are described in Defining a Join in a Master File. The parent-child pointer is stored in the data source.
- KU
Indicates that this is a cross-referenced segment joined
to the data source using a static join defined in the Master File,
and has a one-to-one relationship to the host segment (that is,
it is a unique segment). Joins defined in the Master File are described
in Defining a Join in a Master File. The parent-child pointer is stored in the data source.
- DKM
Indicates that this is a cross-referenced segment joined
to the data source using a dynamic join defined in the Master File,
and has a one-to-many relationship to the host segment. Joins defined
in the Master File are described in Defining a Join in a Master File. The parent-child pointer is resolved at run time, and therefore
new instances can be added without rebuilding.
- DKU
Indicates that this is a cross-referenced segment joined
to the data source using a dynamic join defined in the Master File,
and has a one-to-one relationship to the host segment (that is,
it is a unique segment). Joins defined in the Master File are described
in Defining a Join in a Master File. The parent-child pointer is resolved at run time, and
therefore new instances can be added without rebuilding.
- KL
Indicates that this segment is described in a Master File
defined join as descending from a KM, KU, DKM, or DKU segment in
a cross-referenced data source, and has a one-to-many relationship
to its parent.
- KLU
Indicates that this segment is described in a Master File
defined join as descending from a KM, KU, DKM, or DKU segment in
a cross-referenced data source, and has a one-to-one relationship
to its parent (that is, it is a unique segment).
x
Reference: Usage Notes for SEGTYPE
Note the following rules when using
the SEGTYPE attribute with a FOCUS data source:
-
Alias. SEGTYPE
does not have an alias.
-
Changes. You
can change a SEGTYPE of S[n] or SH[n] to S0 or b, or increase the
number of key fields. To make any other change to SEGTYPE, you must
use the REBUILD facility.
x
Use the SEGTYPE attribute to describe which fields in
a segment are key fields. The values of these fields determine how
the segment instances are sequenced. The keys must be the first
fields in a segment. You can specify up to 255 keys in a segment
that is sorted from low to high (SEGTYPE = Sn), and up to
99 keys in a segment sorted from high to low (SEGTYPE = SHn).
To maximize efficiency, it is recommended that you specify only
as many keys as you need to make each record unique. You can also choose
not to have any keys (SEGTYPE = S0 and SEGTYPE = blank).
Note: Text fields cannot be used as key fields.
x
For segments that have key fields,
use the SEGTYPE attribute to describe the segment sort order. You
can sort a segment instances in two ways:
x
Suppose the following fields
in a segment represent a department code and the employee last name:
|
06345
Jones
|
19887
Smith
|
19887
Frank
|
23455
Walsh
|
21334
Brown
|
If you set SEGTYPE to S1, the department
code becomes the key. (Note that two records have duplicate key
values in order to illustrate a point about S2 segments later in this
example. Duplicate key values are not recommended for S1 and SH1
segments.) The segment instances are sorted as follows:
|
06345
Jones
|
19887
Smith
|
19887
Frank
|
21334
Brown
|
23455
Walsh
|
If you change the field order to put
the last name field before the department code and leave SEGTYPE
as S1, the last name becomes the key. The segment instances are
sorted as follows:
|
Brown
21334
|
Frank
19887
|
Jones
06345
|
Smith
19887
|
Walsh
23455
|
Alternately, if you leave the department
code as the first field, but set SEGTYPE to S2, the segments are
sorted first by the department code and then by last name, as follows:
|
06345
Jones
|
19887
Frank
|
19887
Smith
|
21334
Brown
|
23455
Walsh
|
xDescribing Segment Relationships
The SEGTYPE attribute describes
the relationship of a segment to its parent segment:
- Physical one-to-one
relationships are usually specified by setting SEGTYPE to U. If
a segment is described in a Master File-defined join as descending
from the cross-referenced segment, then SEGTYPE is set to KLU in
the join description.
- Physical one-to-many
relationships are specified by setting SEGTYPE to any valid value
beginning with S (such as S0, SHn, and Sn) to blank,
or, if a segment is described in a Master File-defined join as descending
from the cross-referenced segment, to KL.
- One-to-one joins
defined in a Master File are specified by setting SEGTYPE to KU
or DKU, as described in Defining a Join in a Master File.
- One-to-many
joins defined in a Master File are specified by setting SEGTYPE
to KM or DKM, as described in Defining a Join in a Master File.
xStoring a Segment in a Different Location: LOCATION
By default, all of the segments in a FOCUS data source are stored
in one physical file. For example, all of the EMPLOYEE data source
segments are stored in the data source named EMPLOYEE.
Use the LOCATION attribute to specify that one or more segments
be stored in a physical file separate from the main data source
file. The LOCATION file is also known as a horizontal partition.
You can use a total of 64 LOCATION files per Master File (one LOCATION attribute
per segment, except for the root). This is helpful if you want to
create a data source larger than the FOCUS limit for a single data
source file, or if you want to store parts of the data source in
separate locations for security or other reasons.
There are at least two cases in which
to use the LOCATION attribute:
- Each physical
file is individually subject to a maximum file size. You can use the
LOCATION attribute to increase the size of your data source by splitting
it into several physical files, each one subject to the maximum
size limit. (Read Defining a Join in a Master File to learn if it is more efficient
to structure your data as several joined data sources.)
- You can also
store your data in separate physical files to take advantage of
the fact that only the segments needed for a report must be present.
Unreferenced segments stored in separate data sources can be kept
on separate storage media to save space or implement separate security
mechanisms. In some situations, separating the segments into different
data sources allows you to use different disk drives.
Divided data sources require more careful file maintenance. Be
especially careful about procedures that are done separately to
separate data sources, such as backups. For example, if you do backups
on Tuesday and Thursday for two related data sources, and you restore
the FOCUS structure using the Tuesday backup for one half and the
Thursday backup for the other, there is no way of detecting this
discrepancy.
x
Syntax: How to Store a Segment in a Different Location
LOCATION = filename [,DATASET = physical_filename]
where:
- filename
Is the ddname of the file in which the segment is to be stored.
- physical_filename
Is the physical name of the data source, dependent on the platform.
Example: Specifying Location for a Segment
The following illustrates the use of
the LOCATION attribute:
FILENAME = PEOPLE, SUFFIX = FOC, $
SEGNAME = SSNREC, SEGTYPE = S1, $
FIELD = SSN, ALIAS = SOCSEG, USAGE = I9, $
SEGNAME = NAMEREC, SEGTYPE = U, PARENT = SSNREC, $
FIELD = LNAME, ALIAS = LN, USAGE = A25, $
SEGNAME = HISTREC, SEGTYPE = S1, PARENT = SSNREC, LOCATION = HISTFILE, $
FIELD = DATE, ALIAS = DT, USAGE = YMD, $
SEGNAME = JOBREC, SEGTYPE = S1, PARENT = HISTREC,$
FIELD = JOBCODE, ALIAS = JC, USAGE = A3, $
SEGNAME = SKREC, SEGTYPE = S1, PARENT = SSNREC, $
FIELD = SCODE, ALIAS = SC, USAGE = A3, $
This description groups the five segments
into two physical files, as shown in the following diagram:
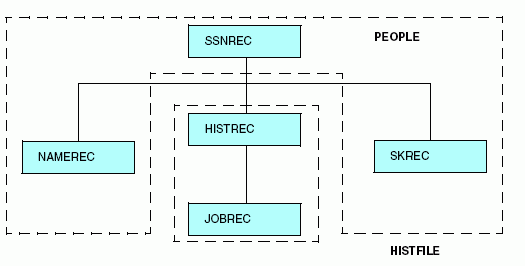
Note
that the segment named SKREC, which contains no LOCATION attribute,
is stored in the PEOPLE data source. If no LOCATION attribute is
specified for a segment, it is placed by default in the same file
as its parent. In this example, you can assign the SKREC segment to
a different file by specifying the LOCATION attribute in its declaration.
However, it is recommended that you specify the LOCATION attribute,
and not allow it to default.
xSeparating Large Text Fields
Text fields, by default, are stored in one physical
file with non-text fields. However, as with segments, a text field
can be located in its own physical file, or any combination of text
fields can share one or several physical files. Specify that you
want a text field stored in a separate file by using the LOCATION
attribute in the field definition.
For example, the text for DESCRIPTION
is stored in a separate physical file named CRSEDESC:
FIELD = DESCRIPTION, ALIAS = CDESC, USAGE = TX50, LOCATION = CRSEDESC ,$
If you have more than one text field, each field can be stored
in its own file, or several text fields can be stored in one file.
In the following example, the text fields
DESCRIPTION and TOPICS are stored in the LOCATION file CRSEDESC.
The text field PREREQUISITE is stored in another file, PREREQS.
FIELD = DESCRIPTION , ALIAS = CDESC, USAGE = TX50, LOCATION = CRSEDESC,$
FIELD = PREREQUISITE, ALIAS = PREEQ, USAGE = TX50, LOCATION = PREREQS ,$
FIELD = TOPICS, ALIAS = , USAGE = TX50, LOCATION = CRSEDESC,$
As with segments, you might want to use the LOCATION attribute
on a text field if it is very long. However, unlike LOCATION segments,
LOCATION files for text fields must be present during a request,
whether or not the text field is referenced.
The LOCATION attribute can be used independently for segments
and for text fields. You can use it for a text field without using
it for a segment. You can also use the LOCATION attribute for both
the segment and the text field in the same Master File.
Note: Field names for text fields in a FOCUS Master File
are limited to 12 characters. Field names for text fields in an
XFOCUS Master File are not subject to this 12 character limitation.
However, for both types of data sources, alias names for these fields can
be up to 66 characters.
xLimits on the Number of Segments, LOCATION Files, Indexes, and Text Fields
The maximum number of segments in a Master File is 64.
There is a limit on the number of different location segments and
text LOCATION files you can specify. This limit is based on the
number of entries allowed in the File Directory Table (FDT) for
FOCUS and XFOCUS data sources. The FDT contains the names of the
segments in the data source, the names of indexed fields, and the
names of LOCATION files for text fields.
x
Reference: FDT Entries for a FOCUS or XFOCUS Data Source
The
FDT can contain 189 entries, of which up to 64 can represent segments
and LOCATION files. Each unique LOCATION file counts as one entry
in the FDT.
Determine the maximum
number of LOCATION files for a data source using the following formula:
Available FDT entries = 189 - (Number of Segments + Number of Indexes)
Location files = min (64, Available FDT entries)
where:
- Location files
Is the maximum number of LOCATION segments and text LOCATION
files (up to a maximum of 64).
- Number of Segments
Is the number of segments in the Master File.
- Number of Indexes
Is the number of indexed fields.
For
example, a ten-segment data source with 2 indexed fields enables
you to specify up to 52 LOCATION segments and/or LOCATION files
for text fields (189 - (10 + 2)). Using the formula, the result
equals 177. However, the maximum number of text LOCATION files must
always be no more than 64.
Note: If you specify a text
field with a LOCATION attribute, the main file is included in the
text location file count.
xSpecifying a Physical File Name for a Segment: DATASET
In addition to specifying a DATASET attribute at the
file level in a FOCUS Master File, you can specify the attribute
on the segment level to specify the physical file name for a LOCATION
segment, or a cross-referenced segment with field redefinitions.
For information on specifying the DATASET attribute at the file
level, see Identifying a Data Source.
Note:
- If you issue a USE command or explicit
allocation for the file, a warning is issued that the DATASET attribute
will be ignored.
- You cannot use
both the ACCESSFILE attribute and the DATASET attribute in the same
Master File.
The segment with the DATASET attribute
must be either a LOCATION segment or a cross-referenced segment.
For cross-referenced segments:
- If field declarations
are specified for the cross-referenced fields, the DATASET attribute
is the only method for specifying a physical file, because the cross-referenced Master
File is not read and therefore is not able to pick up its DATASET
attribute if one is specified.
- If field declarations
are not specified for the cross-referenced fields, it is better
to place the DATASET attribute at the file level in the cross-referenced
Master File. In this case, specifying different DATASET values at
the segment level in the host Master File and the file level of
the cross-referenced Master File causes a conflict, resulting in
a (FOC1998) message.
If DATASET is used in a Master File whose data source is managed
by the FOCUS Database Server, the DATASET attribute is ignored on
the server side because the FOCUS Database Server does not read
Master Files for servicing table requests.
The DATASET attribute in the Master File
has the lowest priority:
- A user explicit
allocation overrides DATASET attributes.
- The USE command
for FOCUS data sources overrides DATASET attributes and explicit
allocations.
Note: If a DATASET allocation is in effect, you must issue
a CHECK FILE command in order to override it by an explicit allocation
command. The CHECK FILE command deallocates the allocation created
by DATASET.
x
Syntax: How to Use the DATASET Attribute on the Segment Level
For a LOCATION
segment:
SEGNAME=segname, SEGTYPE=segtype, PARENT=parent, LOCATION=filename,
DATASET='physical_filename [ON sinkname]',$
For a cross-referenced
segment:
SEGNAME=segname, SEGTYPE=segtype, PARENT=parent, [CRSEGNAME=crsegname,]
[CRKEY=crkey,] CRFILE=crfile, DATASET='filename1 [ON sinkname]',
FIELD=...
where:
- filename
Is the logical name of the LOCATION file.
- physical_filename
Is the platform-dependent physical name of the data source.
- sinkname
Indicates that the data source is located on the FOCUS Database
Server. This attribute is valid for FOCUS data sources.
The syntax on
z/OS is:
{DATASET|DATA}='qualifier.qualifier ...'
or
{DATASET|DATA}='ddname ON sinkname'
On UNIX, the syntax
is:
{DATASET|DATA}='path/filename'
On Windows, the
syntax is:
{DATASET|DATA}='path\filename'
Example: Allocating a Segment Using the DATASET Attribute
On z/OS:
FILE = ...
SEGNAME=BODY,SEGTYPE=S1,PARENT=CARREC,LOCATION=BODYSEG,
DATASET='USER1.BODYSEG.FOCUS',
FIELDNAME=BODYTYPE,TYPE,A12,$
FIELDNAME=SEATS,SEAT,I3,$
FIELDNAME=DEALER_COST,DCOST,D7,$
FIELDNAME=RETAIL_COST,RCOST,D7,$
FIELDNAME=SALES,UNITS,I6,$
On
z/OS with SU:
FILE = ...
SEGNAME=BODY,SEGTYPE=S1,PARENT=CARREC,LOCATION=BODYSEG,
DATASET='BODYSEG ON MYSU',
FIELDNAME=BODYTYPE,TYPE,A12,$
FIELDNAME=SEATS,SEAT,I3,$
FIELDNAME=DEALER_COST,DCOST,D7,$
FIELDNAME=RETAIL_COST,RCOST,D7,$
FIELDNAME=SALES,UNITS,I6,$
On UNIX/USS:
FILE = ...
SEGNAME=BDSEG,SEGTYPE=KU,CRSEGNAME=IDSEG,CRKEY=PRODMGR,
CRFILE=PERSFILE,DATASET='/u2/prod/user1/idseg.foc',
FIELD=NAME,ALIAS=FNAME,FORMAT=A12,INDEX=I, $
On Windows:
FILE = ...
SEGNAME=BDSEG,SEGTYPE=KU,CRSEGNAME=IDSEG,CRKEY=PRODMGR,
CRFILE=PERSFILE,DATASET='\u2\prod\user1\idseg.foc',
FIELD=NAME,ALIAS=FNAME,FORMAT=A12,INDEX=I, $
xTimestamping a FOCUS Segment: AUTODATE
Each segment of a FOCUS data source can have a timestamp
field that records the date and time of the last change to the segment.
This field can have any name, but its USAGE format must be AUTODATE.
The field is populated each time its segment instance is updated.
The timestamp is stored as format HYYMDS, and can be manipulated for
reporting purposes using any of the date-time functions.
In each segment of a FOCUS data source, you can define a field
with USAGE = AUTODATE. The AUTODATE field cannot be part of a key
field for the segment. Therefore, if the SEGTYPE is S2, the AUTODATE
field cannot be the first or second field defined in the segment.
The AUTODATE format specification is supported only for a real
field in the Master File, not in a DEFINE or COMPUTE command or
a DEFINE in the Master File. However, you can use a DEFINE or COMPUTE
command to manipulate or reformat the value stored in the AUTODATE
field.
After adding an AUTODATE field to a segment, you must REBUILD
the data source. REBUILD does not timestamp the field. It does not
have a value until a segment instance is inserted or updated.
If a user-written procedure updates the AUTODATE field, the user-specified
value is overwritten when the segment instance is written to the
data source. No message is generated to inform the user that the
value was overwritten.
The AUTODATE field can be indexed. However, it is recommended
that you make sure the index is necessary, because of the overhead
needed to keep the index up to date each time a segment instance
changes.
If you create a HOLD file that contains the AUTODATE field, it
is propagated to the HOLD file as a date-time field with the format
HYYMDS.
x
Syntax: How to Define an AUTODATE Field for a Segment
FIELDNAME = fieldname, ALIAS = alias, {USAGE|FORMAT} = AUTODATE ,$where:
- fieldname
Is any valid field name.
- alias
Is any valid alias.
Example: Defining an AUTODATE Field
Create the EMPDATE data source by performing
a REBUILD DUMP of the EMPLOYEE data source and a REBUILD LOAD into
the EMPDATE data source. The Master File for EMPDATE is the same
as the Master File for EMPLOYEE, with the FILENAME changed and the
DATECHK field added:
FILENAME=EMPDATE, SUFFIX=FOC
SEGNAME=EMPINFO, SEGTYPE=S1
FIELDNAME=EMP_ID, ALIAS=EID, FORMAT=A9, $
FIELDNAME=DATECHK, ALIAS=DATE, USAGE=AUTODATE, $
FIELDNAME=LAST_NAME, ALIAS=LN, FORMAT=A15, $
.
.
.
To add the timestamp
information to EMPDATE, run the following procedure:
SET TESTDATE = 20010715
TABLE FILE EMPLOYEE
PRINT EMP_ID CURR_SAL
ON TABLE HOLD
END
MODIFY FILE EMPDATE
FIXFORM FROM HOLD
MATCH EMP_ID
ON MATCH COMPUTE CURR_SAL = CURR_SAL + 10;
ON MATCH UPDATE CURR_SAL
ON NOMATCH REJECT
DATA ON HOLD
END
Then reference the AUTODATE
field in a DEFINE or COMPUTE command, or display it using a display
command. The following request computes the number of days difference between
the date 7/31/2001 and the DATECHK field:
DEFINE FILE EMPLOYEE
DATE_NOW/HYYMD = DT(20010731);
DIFF_DAYS/D12.2 = HDIFF(DATE_NOW, DATECHK, 'DAY', 'D12.2');
END
TABLE FILE EMPDATE
PRINT DATECHK DIFF_DAYS
WHERE LAST_NAME EQ 'BANNING'
END
The output is:
DATECHK DIFF_DAYS
------- ---------
2001/07/15 15:10:37 16.00
x
Reference: Usage Notes for AUTODATE
- PRINT * and
PRINT.SEG.fld print the AUTODATE field.
- The FOCUS Database
Server updates the AUTODATE field per segment using the date and
time on the Server.
- Maintain processes
AUTODATE fields at COMMIT time.
- DBA is permitted
on the AUTODATE field. However, when unrestricted fields in the segment
are updated, the system updates the AUTODATE field.
- The AUTODATE
field does not support the following attributes: MISSING, ACCEPT, and HELPMESSAGE.