How to: |
When you create a Master File, you create a default representation of a hierarchy. Sometimes, however, you may not want to follow the default route to retrieve records. Two such instances might be when:
- Your IF criteria screen a segment at the bottom of a subtree.
- You are processing a multi-path report with IF criteria or sort phrases that are not on a common path.
When these situations occur, using WebFOCUS you can specify a new entry segment (root) at execution time for a specific request. This process is called file inversion, because the parent/descendant relationships along the path linking the original root and the new root are reversed; other parent/descendant relationships remain unchanged.
Note: File inversions only change the file views; they do not affect the data.
TABLE FILE filename.fieldwhere:
- field
May be any field in the new root segment.
For example, to invert the EMPFULL file so that the office segment is the new root, specify the field OFFICE_CODE:
TABLE FILE EMPFULL.OFFICE_CODE
You can also display a diagram of the inverted file with the CHECK FILE command (include the RETRIEVE option for a subtree diagram):
CHECK FILE filename.fieldname PICTURE [RETRIEVE]You cannot invert a Master File if:
- The path linking the old and new roots passes through segments that have a CALC- or index-based relationship.
- The GETOWN parameter in the ACCESS File for a set-based relationship is set to N.
- It is an LRF Master File.
File inversion is a simple solution to two common problems:
- Denied access because the segment is on the wrong sort path.
- Denied access because the field named in an IF test is not on the root path.
In addition to solving the sort path problem, file inversion can improve I/O efficiency which, in turn, minimizes production costs.
Consider this request:
TABLE FILE EMPFULL LIST SKILL_LEVEL BY SALARY_GRADE END
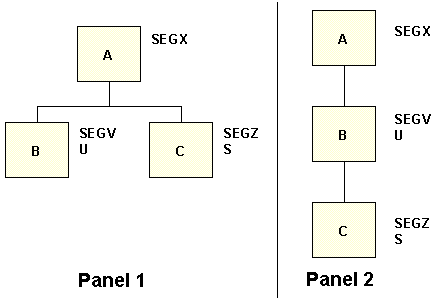
In panel 1 of the following figure, an error occurs because segments C and B are not on the same path. Therefore, you must use an inverted view:
TABLE FILE EMPFULL.SALARY_GRADE LIST SKILL_LEVEL BY SALARY_GRADE END
In the inverted view (panel 2), segment C is a descendant of segment B. Using this inverted view, the request can be executed.
As this request is executed, record occurrences multiply. Every record of segment C is paired with every record in segment B. If, for example, A had two B descendants and four C descendants, the report would contain eight lines of output. This effect is advantageous when it is necessary to pair every record associated with one linkpath to a record associated with another linkpath. Record pairing may produce undesirable results when the inverted segments are not directly related to each other.
If you use file inversion in conjunction with MISSING=ON, you may access orphan record occurrences that could not be accessed with the default Master File. An orphan record occurrence is one that has no parent record connection. Due to the network structure of IDMS/DB, any hierarchical view may contain orphans. IDMS/DB set connection options OA, OM, or MM indicate the possibility of orphans. Inversion enables the adapter to reconstruct the IDMS/DB relationships, so that these orphans can be retrieved.