This section provides detailed descriptions of new features
for SQL adapters.
x
This section provides detailed descriptions of new features
for all SQL adapters.
x
Selectively Controlling FOCUS Function Optimization Through FEATOPT
The optimization of some FOCUS features and functions
can now be controlled using the FEATOPT SET command. This enables
users to switch off SQL optimization for a particular function or
feature when the optimization might produce unsatisfactory results.
The syntax is:
ENGINE SQL<engine> SET FEATOPT <focus_feature> OFF
The default value is ON, which means that the given function
will be passed to SQL or the feature will be optimized. The setting
can be applied to the following FOCUS features and functions:
- ** (power operator: x**y)
| |
| |
| |
| |
| - RANK (BY [HIGHEST/LOWEST])
|
| |
| |
- DEFFUN (defined functions)
| |
| |
| |
| |
| |
| - S_CONCAT (strong concatenation)
|
| - W_CONCAT (weak concatenation)
|
| |
x
Support for SELECT ON TABLE HOLD FORMAT SAME_DB
An SQL SELECT statement with all the sources in the
same relational database can now be used with an ON TABLE HOLD AS name FORMAT
SAME_DB command. This uses the underlying database capabilities,
such as INSERT INTO ... SELECT, that provide much faster throughput
than alternative methods.
x
Full Synonym Support Added for SQL Strings
Synonyms created for SQL strings
without parameters can now be used in the following commands/situations:
- JOIN
- WHERE clause (passed
to SQL)
- Aggregation (passed
to SQL)
- As a result of the
ON TABLE HOLD FORMAT SAME_DB (passed to SQL).
The SQL strings will be processed as subqueries embedded in a
FROM clause of the generated SELECT query. The new behavior is triggered
by the presence of a SUBQUERY=Y keyword in the Access File describing
the location of the SQL string file. SUBQUERY=Y is not permitted
for Access Files describing SQL strings that use SQL parameter
markers, for example '?' or ':001'.
x
AUTOINCREMENT for PACK Fields Added
Surrogate Keys Support has been enhanced and now includes
fields defined with the PACK data type. Therefore, auto-incrementing
can now be assigned to PACK data type fields.
The AUTOINCREMENT field uses the numeric data type with the widest
value range allowed by a particular DBMS for the autonumbering,
either DECIMAL, BIGINT, SERIAL, SERIAL8, or BIGSERIAL.
AUTOINCREMENT is supported by the following adapters:
- DB2 (LUW, z/OS,
and i5)
- Informix
- JDBC (Derby)
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- Red Brick
- Sybase (ASE and IQ)
- Teradata
x
BY HIERARCHY Reporting Available From SQL and Hold Files
BY HIERARCHY reporting now can be applied to relational
data sources. The end user is responsible for properly representing
the hierarchy in the Master File. The Dimension Builder in the Data
Management Console enables you to assign the properties of the hierarchy.
x
Using Segment Names as Tags When Generating SQL
The default tag name used by the server SQL generator
is T1, T2, and so on. A new setting has been introduced that enables
you to assign tag names to match the segment names that contain
the referenced fields. To switch to using the SEGNAMEs as tag names,
use the following setting:
SQL engine SET SQLTAG SEGNAME
To switch back to the T1, T2 tag names in the generated SQL,
which is the default, use the following setting:
SQL engine SET SQLTAG SEGNUM
x
Support for FOCUS Amper Variables as SQL String Parameters
The ability to run a request against a synonym for an
SQL string has been enhanced to allow the parameterization of the
SQL string using Dialogue Manager global variables. After the synonym
has been created against the relational adapter where the SQL will
be processed, global variables can be added to the source SQL file.
The Synonym Editor is then used to add the Variable Declarations.
The following example illustrates this feature. The .sql file
contains the following:
SELECT COLUMNA, COLUMNB, COLUMNC FROM test1
WHERE COLUMNA = 'test'
The synonym created will have three fields. The SQL can now be
edited to add a global variable in place of the WHERE value test:
WHERE COLUMNA = &&VARIABLE1
The Synonym Editor is then used to add the variable declaration:
FILENAME=test1, SUFFIX=SQLMSS , $
VARIABLE NAME=&&VARIABLE1, QUOTED=ON, $
The global variable can be set prior to running a request:
-SET &&VARIABLE1 = 'NEWVALUE'
TABLE FILE TEST1
PRINT *
END
x
Specifying a Time Limit to Log on to a Data Source
A new LOGINTIMEOUT setting has been added to the Session
Parameter settings. It enables you to specify the amount of time
that an adapter should allow to complete a log on to a data source
before returning an error.
The default value is adapter-specific, and is generally 15 to
20 seconds.
The following adapters support this setting:
- 1010data
- Cache
- DB2 CLI (excluding
IBM i and z/OS platforms)
- Excel
- Greenplum
- Hive
- Hyperstage
- Interplex
- JDBC
- Metamatrix
- Microsoft Access
- Microsoft SQL Server
(both JDBC and OLEDB)
- MySQL
- Neoview
- Netezza
- ODBC
- parAccel
- PostgreSQL
- Progress
- PSQL
- Red Brick
- Sand/Nucleus
- SQLBase
- Teradata ODBC
- Transoft
- Unidata
x
Procedure: How to Specify a Time Limit to Log on to a Data Source
-
Right-click
a configured adapter folder and select Change Settings.
The Change Settings page opens.
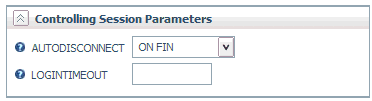
-
In the Controlling
Session Parameters section, enter the number of seconds in the LOGINTIMEOUT field.
Note: The Session Parameters available will vary
by adapter.
-
Click Save.
xAdapter for EMC Greenplum
The Adapter for EMC Greenplum has been introduced in
this release and is available as a named adapter on the Web Console
in the SQL folder.
This adapter provides greater flexibility for SQL optimization
than generic JDBC used in previous releases.
xAdapter for Microsoft SQL Server
This section provides detailed descriptions of new features
for the Adapter for Microsoft SQL Server.
x
Primary Key Order Respected by CREATE SYNONYM Process
A new Create Synonym mechanism ensures that a Primary
Key is prioritized, regardless of how and in what order it was created
in the DBMS.
The Access File KEYS attribute now respects the priority of the
Primary Key with the following constraints:
- If the Primary Key
field exists, it will be used first.
- If a table has no
Primary Key, a unique index field or fields will be used in the
KEYS attribute.
xAdapter for Microsoft SQL Server and Sybase
This section provides detailed descriptions of new features
for the Adapters for Microsoft SQL Server and Sybase.
x
TSTOPACK Function: Converting a Microsoft SQL Server or Sybase Timestamp Column to Packed Decimal
This function applies to the Microsoft SQL Server and
Sybase adapters only.
Microsoft SQL Server and Sybase have a data type called TIMESTAMP.
Rather than containing an actual timestamp, columns with this data
type contain a number that is incremented for each record inserted
or updated in the data source. This timestamp comes from a common
area, so no two tables in the database have the same timestamp column value.
The value is stored in Binary(8) or Varbinary(8) format in the table,
but is returned as a double-wide alphanumeric column (A16). You
can use the TSTOPACK function to convert the timestamp value to
packed decimal.
x
Syntax: How to Convert a Microsoft SQL Server or Sybase Timestamp Column
to Packed Decimal
TSTOPACK(tscol, output);
where:
- tscol
-
A16
Is the timestamp
column to be converted.
- output
P21
Is the name of the field that
contains the result or the format of the output value enclosed in
single quotation marks (').
Example: Converting a Microsoft SQL Server Timestamp Column
to Packed Decimal
The following CREATE TABLE command creates
a SQL Server table name TSTEST that contains an integer counter
column named I and a timestamp column named TS:
SQL SQLMSS
CREATE TABLE TSTEST (I INT, TS timestamp) ;
END
The Master
File for the TSTEST data source follows. The field TS represents
the TIMESTAMP column:
FILENAME=TSTEST, SUFFIX=SQLMSS , $
SEGMENT=TSTEST, SEGTYPE=S0, $
FIELDNAME=I, ALIAS=I, USAGE=I11, ACTUAL=I4,
MISSING=ON, $
FIELDNAME=TS, ALIAS=TS, USAGE=A16, ACTUAL=A16, FIELDTYPE=R, $
Note: When you generate a synonym
for a table with a TIMESTAMP column, the TIMESTAMP column is created
as read-only (FIELDTYPE=R).
TSTOPACK
converts the timestamp column TS to packed decimal:
DEFINE FILE TSTEST
TSNUM/P21=TSTOPACK(TS,'P21');
END
TABLE FILE TEST64
PRINT I TS TSNUM
END
The output is:
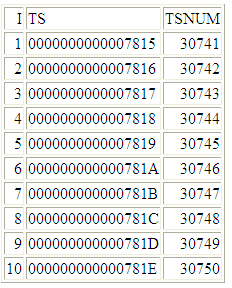
x
This section provides detailed descriptions of new features
for the Adapter for Oracle.
x
Support for XMLType Data Type
The Create Synonym facility for the Adapter for Oracle
can now describe a column defined in the DBMS as native XMLType.
This provides support for the XMLType in various server operations.
Oracle XMLType can be accessed through the getCLOBVal() native
method using any of two techniques:
- Oracle view, where
getCLOBVal() converts XMLType into CLOB.
- DEFINE field that
uses DB_EXPR() applied to XMLType column(s), if the first technique
is not desirable.
For example, with an Oracle table with following structure:
ORAXML
---------------------
INTFLD INT
XMLFLD XMLType
The first technique requires you to use Create View in Oracle:
CREATE VIEW ORAXML_V (I_FLD,X_FLD)
AS
SELECT a.INTFLD,
a.XMLFLD.getCLOBVal()
FROM ORAXML a;You can then use the standard approach which combines Oracle
and XML synonyms, as described in the documentation for the Adapter
for XML.
The second technique does not require using Create View in Oracle.
The virtual field can be used instead.
Lets assume the server synonym ORAXML_S is created for the table
above and the XMLFLD is mapped as TX50L, TX. Then the following
statements:
DEFINE FILE ORAXML_S
XMLFLD/A32767 WITH INTFLD=DB_EXPR(T1.XMLFLD.getCLOB());
END
TABLE FILE ORAXML_S PRINT XMLFLD WHERE INTFLD EQ <value>
END
will be optimized as:
SELECT
(T1.XMLFLD.getCLOBVal()),
T1."INTFLD"
FROM
ORAXML T1
WHERE
T1."INTFLD" = <value>
and will bring Oracle XMLType data into the report.
x
Support for NCLOB Data Type Added
The Adapter for Oracle now can describe report and update
Oracle columns that are defined as NCLOB (National Character Large
Objects) when the Reporting Server is configured for Unicode.
Note:
- The Oracle NCLOB
columns are described in the Master File as USAGE=TX50, ACTUAL=TX.
- As with CLOB, NCLOB
can be used in WHERE clauses only for pattern matching, for example,
%pattern%. It cannot be used for a comparison search, such as =/!=/<>/>=/<=.