Creating a Quick ETL Copy
The Quick ETL Copy option generates a
simple Data Flow without using the Data Flow
designer. For the selected table(s), all rows and columns are
copied to new table(s).
Although no transformations or where conditions
are generated, the Data Flow can still be opened as such and additional
criteria can be added.
x
Procedure: How to Create a Quick ETL Copy for a Single Table
-
Right-click
a synonym name and select Quick ETL Copy.
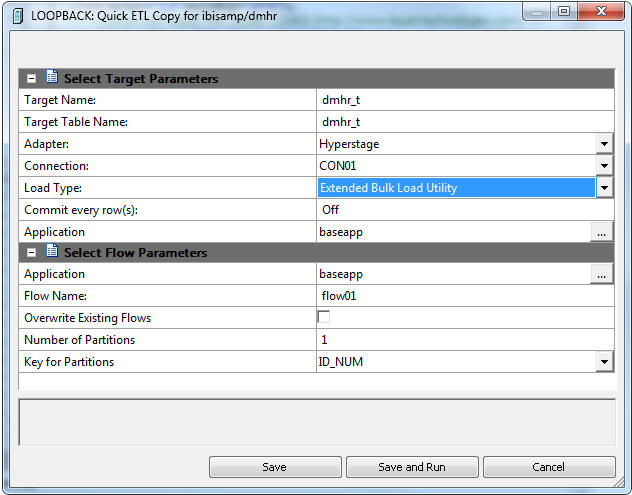
The Quick ETL Copy dialog box opens, as shown in the following
image.
-
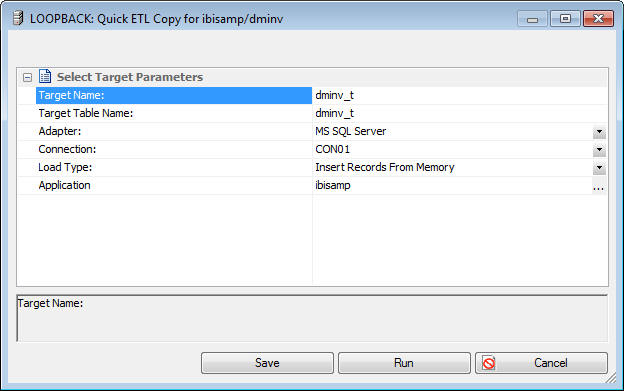
Target Name
-
The synonym name for the target table.
-
Target Table Name
-
The name of the target table name in the database.
-
Adapter
-
Select a database configured as an adapter from the drop-down menu.
-
Connection
-
Select a connection for the selected adapter from the drop-down menu.
-
Load Type
-
Specifies the method DataMigrator uses
to load data. Select Insert Records from Memory, Bulk
Load Utility via Disk File, or Extended Bulk
Load Utility if the database supports either of these
options.
-
Application
-
The application directory where the target tables and generated
flow will be stored.
When Bulk Load Utility
via Disk File or Extended Bulk Load is used, additional parameters
are available. For more information, see Load Options.
-
Select the
application directory where to save the flow from the Application field
in the Select Flow Parameters section.
-
Click Save or Run. Two
flows will be created, a process flow with the name you specified
and a data flow with the name followed by the table name. For example,
flow01_dmhr. The process flow calls the data flow to copy the table.
x
Reference: Parallelization and Partitioning
For faster processing when using
Quick ETL Copy for a single table that has one more numeric keys,
the table can be divided into multiple partitions and one job run
for each partition.
You select a column to use and values
are calculated to divide the table by selecting a range of values
to partition the source table. When the flow is run, multiple instances
are run, one for each partition.
The following additional
options appear:
-
Number of Partitions
-
The number of partitions to create. The default is one partition
and the entire table is processed in a single flow.
-
Key for Partitions
-
A drop-down menu showing the numeric key columns in the source
table. Select the column to be used for partitioning the table.
x
Procedure: How to Create a Quick ETL Copy for Multiple Tables
-
Right-click
an application directory and select Quick ETL Copy.
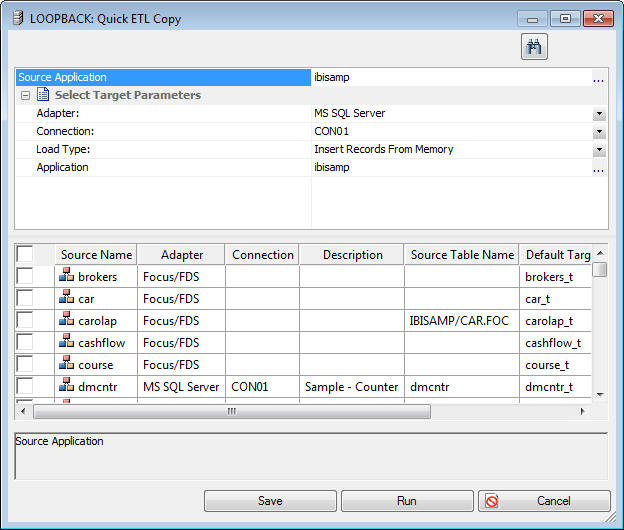
The Quick ETL Copy dialog box opens, as shown in the following
image.
-
Select the
tables you want to copy by selecting the check box in the first column.
Doing so allows you to change the Target Name, which is the synonym,
and the Target Table Name, which is the name of the table in the
database.
-
Click Save or Run. Two
flows will be created, a process flow with the name you specified
and a data flow with the name followed by the table name. For example,
flow01_dmreps. The process flow calls all of the data flows.
x
Reference: Quick Copy for Hyperstage with Parallel Load
For
Hyperstage, there is an additional Load Type of Extended Bulk Load
Utility that supports parallel load sessions. When the Commit every
row(s) option has a value other than Off, which is the default,
it specifies the number of rows to load in each session. When the
number is reached, a new session is started. This feature is most
useful for large data volumes because the recommended minimum value
is 1 million. The number of partitions indicates the maximum number
of partitions to use.
If the Hyperstage Distributed Load Processor
is installed and its location specified, when the Hyperstage adapter
is configured an additional option named Use Distribute Load Processor
becomes available. This alternate load method reduces the CPU time
used.