Customizing the SQL Server Analysis Services Environment
The Adapter for SQL Server Analysis Services provides
several parameters for customizing the environment and optimizing
performance. This topic provides an overview of customization options.
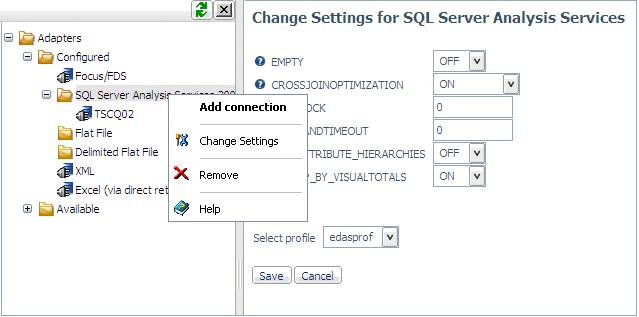
Tip: You can change this setting from the Web Console
by clicking Data Adapters in the navigation
pane, clicking the name of a configured adapter, and choosing Change
Settings from the menu. The Change Settings pane opens.
xSpecifying a Timeout Limit
TIMEOUT specifies the number of seconds the adapter will wait
for a response after it issues a request to SQL Server Analysis
Services.
x
Syntax: How to Specify a Timeout Limit
ENGINE SSAS SET COMMANDTIMEOUT {nn|0}where:
- nn
Is the number of seconds before a timeout occurs. 30 is the
default value.
- 0
Represents an infinite period to wait for response.
Note: If
you do not specify a COMMANDTIMEOUT value, the current SQL Server
Analysis Services default timeout setting is used.
xActivating NONBLOCK Mode and Issuing a TIMEOUT Limit
You can use the NONBLOCK command to prevent runaway queries.
The Adapter for SQL Server Analysis Services uses non-blocking protocol
for query execution.
TIMEOUT specifies the number of seconds the adapter will wait
for a response after you issue an SQL request to SQL Server Analysis
Services.
x
Syntax: How to Activate NONBLOCK Mode and Issue a TIMEOUT Limit
ENGINE SSAS SET NONBLOCK n [TIMEOUT m]
where:
- n
Is the polling period in seconds.
- m
Is the total timeout after which the query is terminated
if it does not get completed.
xRetrieving Rows (Report Lines) Without Values
You can use the SET EMPTY command to display or suppress rows,
or report lines, where all the selected measure columns have empty
values.
x
Syntax: How to Control EMPTY Mode
ENGINE SSAS SET EMPTY {ON|OFF}where:
- ON
Does not suppress rows, or report lines, without values.
- OFF
Suppresses rows, or report lines, without values. This is
the default.
Example: Activating EMPTY Mode
In
the following request, EMPTY is set to OFF. Therefore, rows (report
lines) with no data are suppressed.
TABLE FILE SALES
PRINT Profit
BY City
END
The partial output is:
City Profit
---- ------
Albany 8,516.532900000
Altadena 3,345.876900000
Anacortes 956.535100000
With EMPTY set to ON,
the rows (report lines) with no data are displayed.
City Profit
---- ------
Acapulco .
Albany 8,516.532900000
Altadena 3,345.876900000
Anacortes 956.535100000
xIncluding System Hierarchies in Synonyms
Some hierarchies are flagged as user-defined. By default,
synonyms include fields only for user-defined hierarchies. To create
synonyms that include fields for all hierarchies in a cube, issue
the ENGINE SSAS SET SYSTEMHIERACHIES command in any supported profile.
You can also select this option when creating a synonym by checking
the Include System-Enabled Hierarchies check
box.
Note: You can redirect UDA references to attribute hierarchies
without including them in the synonym using the SET USE_ATTRIBUTE_HIERARCHIES
command. For more information, see Redirecting UDA References to Attribute Hierarchies.
x
Syntax: How to Include System Hierarchies in Synonyms
ENGINE SSAS SET SYSTEMHIERARCHIES {ON|OFF}where:
- ON
Includes fields for all hierarchies when creating a synonym.
- OFF
Includes fields only for those hierarchies flagged as user-defined
when creating a synonym. OFF is the default value.
xUsing the MDX VISUALTOTALS Function
To retrieve data from a SSAS cube, the adapter translates the
WebFOCUS request to MDX, the language that is used by the SSAS engine.
SSAS then returns the cells containing values of the selected measures
for the specified members.
The values stored in the cube are aggregates
resulting from rolling up measures along the cube dimensions when
the cube was processed, and are based on rolling up all the underlying
members of the hierarchy. Some reports perform selections on hierarchy
levels below the levels selected for display. For example:
TABLE FILE ADVENTURE_WORKS
WRITE INTERNET_SALES_AMOUNT
BY COUNTRY
WHERE STATE_PROVINCE EQ 'California' OR 'New York'
END
The resulting report will display the value of the Internet
Sales Amount measure for the hierarchy member United States.
There are two possible approaches to what is the correct value to show:
- Show the value for the hierarchy member United States as
it exists in the cube (having been rolled up from values of all
the underlying members). This is called a full rollup.
- Show the value for the hierarchy member United States rolled
up based on California and New York only.
This is called a visual total.
By default, the adapter uses option 2 and displays visual totals.
To produce the proper result based on the report selection criteria
such as WHERE/IF clauses for level hierarchies, or WHEN clauses
for parent/child hierarchies (with account for measure calculations, custom
member rollups, etc.), the adapter uses the MDX VISUALTOTALS function,
thus delegating the rollup to the SSAS engine.
When this option is in effect, the displayed values are determined
by the report selection criteria and dimension levels referenced
in the sort phrases (BY and ACROSS) for level hierarchies, or explicit
member selection for Parent/Child hierarchies and dimensions not
referenced by sort phrases.
The type of rollup to perform is controlled by the adapter parameter
setting ROLLUP_BY_VISUALTOTALS. You can change the default value
using the Change Settings panel in the Web
Console. For information, see How to Change the Default ROLLUP_BY_VISUALTOTALS Setting.
In the Synonym Editor, you can set a
ROLLUP_BY_VISUALTOTALS value for:
x
Syntax: How to Enable Rollup by Visual Totals in a Profile or FOCEXEC
Visual
Totals mode is enabled by the following setting that can be issued
in a FOCEXEC or a server or user profile.
ENGINE SSAS SET ROLLUP_BY_VISUALTOTALS {ON|OFF}
where:
-
ON
-
Uses the MDX VISUALTOTALS function to recalculate measure
values so that, on the report output, they reflect only those members
selected in the report request. ON is the default value
- OFF
-
Retrieves values stored in the cube without having them recalculated
based on the member selections in the report request.
x
Procedure: How to Change the Default ROLLUP_BY_VISUALTOTALS Setting
By
default, the MDX VISUAL TOTALS function is enabled. To change the
default:
-
Click Adapters on the menu bar.
-
Right-click the adapter name
and select Change Settings from the context
menu.
-
Select ON or OFF from the ROLLUP_BY_VISUALTOTALS
drop-down list:
-
Click Save.
The setting is saved in the server profile, edasprof.prf.
x
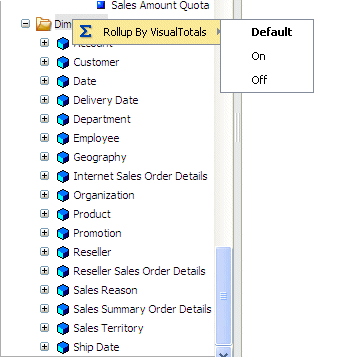
Procedure: How to Change the ROLLUP_BY_VISUALTOTALS Setting for All Hierarchies in a Synonym
Before
you make any changes, all hierarchies within all synonyms inherit
the default ROLLUP_BY_VISUALTOTALS value set in the server profile.
-
Open the synonym in the Synonym Editor.
-
Right-click the dimensions folder
and mouse over Rollup by VisualTotals from
the context menu.
-
Select one of the following options:
-
Default, which inherits the value from the
value set in the server profile.
-
On, which turns ROLLUP_BY_VISUALTOTALS ON for all hierarchies
in all dimensions. You can then change the value for specific dimensions
or for specific hierarchies.
-
Off, which turns ROLLUP_BY_VISUALTOTALS
OFF for all hierarchies in all dimensions. You can then change the
value for specific dimensions or for specific hierarchies.
x
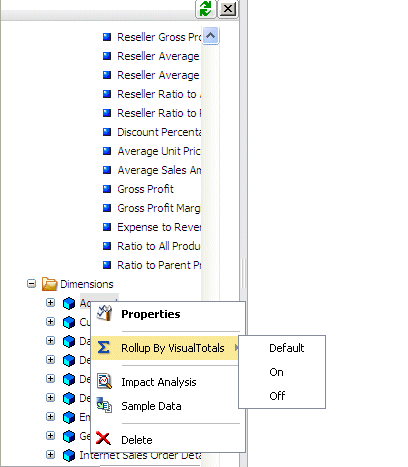
Procedure: How to Change the ROLLUP_BY_VISUALTOTALS Setting for All HIerarchies Within a Dimension
Before
you make any changes, all hierarchies within all dimensions inherit
the ROLLUP_BY_VISUALTOTALS value set for the synonym (which may have
been the default setting inherited from the server profile).
-
Open the synonym in the Synonym Editor.
-
Right-click the dimenion name
and mouse over Rollup by VisualTotals from
the context menu.
-
Select one of the following options:
-
Default, which inherits the value from the
value set for the synonym.
-
On, which turns ROLLUP_BY_VISUALTOTALS ON for all hierarchies
in that dimension. You can then change the value for specific hierarchies.
-
Off, which turns ROLLUP_BY_VISUALTOTALS
OFF for all hierarchies in that dimension. You can then change the
value for specific hierarchies.
x
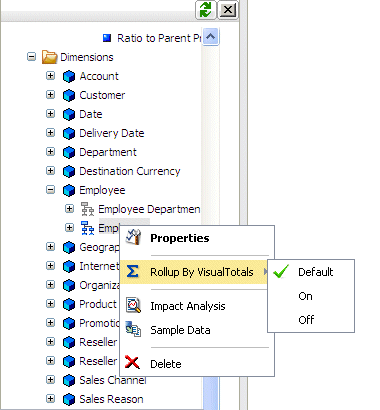
Procedure: How to Change the ROLLUP_BY_VISUALTOTALS Setting for a Hierarchy
Before
you make any changes, all hierarchies within a dimension inherit
the default ROLLUP_BY_VISUALTOTALS value set for the dimension (which may
be the value inherited from the synonym).
-
Open the synonym in the Synonym Editor.
-
Right-click the hierarchy name
and mouse over Rollup by VisualTotals from
the context menu.
-
Select one of the following options:
-
Default, which inherits the value from the
value for the dimension.
-
On, which turns ROLLUP_BY_VISUALTOTALS ON for that hierarchy
in that dimension.
-
Off, which turns ROLLUP_BY_VISUALTOTALS
OFF for that hierarchy in that dimension.
x
Syntax: How to Query SSAS Adapter Settings
The
following command displays all settings in effect at the time it
is issued.
ENGINE SSAS ?
For
example:
(FOC11351) EXCLUSION OF EMPTY CELLS FROM REPORT - ON
(FOC11350) CROSSJOIN OPTIMIZATION - ON
(FOC11352) NONBLOCK OPTION - OFF, POLLING INTERVAL - N/A, TIMEOUT - default
(FOC11366) USE ATTRIBUTE HIERARCHIES - OFF
(FOC11369) DEFAULT FOR ROLLUP_BY_VISUALTOTALS - ON
xRedirecting UDA References to Attribute Hierarchies
UDAs (User-Defined Attributes) are Properties that are represented
by Master File fields with the attribute PROPERTY=ATTRIBUTE. They
correspond to SSAS metadata entities defined in the MDSCHEMA_PROPERTIES
Rowset for hierarchies and their levels. In the Business Management
Studio, these entities are created as Attribute Relationships that link
attributes comprising hierarchy levels to other related attributes.
Examples of such properties/attribute relationships could be Color
and Net Weight for Product, or Address, Phone Number and Gender
for Customer.
By default, SSAS creates a separate attribute hierarchy for each
dimension attribute. The members of these hierarchies contain aggregated
values for distinct values of the attribute. Some of these aggregations
might or might not have business sense. For example, aggregation
of Sales Amount by customer gender might make sense, while aggregation
by phone number does not.
Within the current implementation of the SSAS Adapter, a BY clause
determines the level at which aggregated data is extracted from
a cube. Therefore, if COLOR is a field referencing the Color UDA,
the BY COLOR clause causes individual members of the Product hierarchy
level to be extracted. It is equivalent to BY COLOR BY PRODUCT NOPRINT.
To see values aggregated by Color, you can reference the Master
File field that was created for the corresponding level of the Color
attribute hierarchy. However, this might be inconvenient for the
following reasons:
- By default, attribute hierarchies are not included in a
Master File. If you want them to be included, you must click the Include
System-Enabled Hierarchies check box at synonym creation
time.
- If, at synonym creation time, the user requests inclusion of
attribute hierarchies, the Master File can become very large and
difficult to present visually.
- There is no visual link between a hierarchy level and the related
attribute hierarchies.
If you issue the adapter SET USE_ATTRIBUTE_HIERARCHIES ON command,
the adapter automatically interprets references to UDA fields as
references to the corresponding attribute hierarchies. Therefore,
although the attribute hierarchies are not included in the Master
File, the adapter will use them to retrieve the aggregated measure
values when a request references the UDA resulting from the attribute
relationship created for this attribute.
x
Syntax: How to Redirect UDA References to Attribute Hierarchies
ENGINE SSAS SET USE_ATTRIBUTE_HIERARCHIES {ON|OFF}where:
- ON
Redirects UDA references to corresponding attribute hierarchies.
- OFF
Does not redirect UDA references to attribute hierarchies.
OFF is the default value.
Note: This
setting applies only to Master Files created with level hierarchies.
Example: Effect of Redirecting UDA References to Attribute Hierarchies
In the Adventure_Works Master File,
the Product dimension has a level named Product with a user-defined
attribute (UDA) named Color. The following request sums Internet
Sales Amount by Subcategory and Color. It does not mention Product:
TABLE FILE ADVENTURE_WORKS
WRITE INTERNET_SALES_AMOUNT
BY SUBCATEGORY1
BY COLOR
WHERE SUBCATEGORY1 LIKE 'S%'
END
The setting USE_ATTRIBUTE_HIERARCHIES
OFF (which is the default), results in the following report in which
the values by Color are not aggregated along Product. A separate line
is generated for each product (to see the product names, add a BY
PRODUCT phrase after the BY COLOR phrase):
Subcategory Color Internet Sales Amount
----------- ----- ---------------------
Shorts Black $21,276.96
$24,636.48
$25,406.37
Socks White $2,679.02
$2,427.30However, the setting ENGINE SSAS SET
USE_ATTRIBUTE_HIERARCHIES ON results in the following report in
which the values for Color are automatically aggregated by Product:
Subcategory Color Internet Sales Amount
----------- ----- ---------------------
Shorts Black $71,319.81
Socks White $5,106.32
x
The Adapter for SQL Server Analysis Services (SSAS)
supports a number of modes of operation for accelerating the performance
of queries that deal with large volumes of data, particularly those
that require instantiation of large numbers of cells. Since the
number of cells resulting from the query is equal to the product
of cardinalities of member sets selected for each of the referenced
dimensions, a very large number of cells can be involved.
These options may speed up or, under some circumstances, slow
down particular queries. Since it is difficult to predict which
approach will be most effective in a particular situation, it is
useful to try various combinations of options for queries with slow
response times to determine which produces the best performance
results.
x
Syntax: How to Accelerate Query Performance Using CROSSJOINOPTIMIZATION
Used
in conjunction with the SET EMPTY OFF command, the CROSSJOINOPTIMIZATION
command usually significantly accelerates queries that involve two
or more large dimensions. The syntax is
ENGINE SSAS SET CROSSJOINOPTIMIZATION {ON|OFF|NONEMPTY}
where:
-
ON
-
Optimizes queries by generating a MDX statement with CROSSJOINs
of the sets of members of referenced dimensions on the ROWS axis
instead of generating an MDX statement with each dimension on a
separate axis. ON is the default value.
When SET EMPTY is
OFF (the default), this technique reduces the amount of data passed
from the SQL Analysis Services client to the adapter by delegating
the screening of empty tuples of data to the Analysis Services engine.
The reduction is especially dramatic when low dimension levels on
many dimensions are involved. (If EMPTY is ON, this option will
not reduce the amount of data passed from the client to the adapter.)
- OFF
-
Suppresses CROSSJOIN optimization. This is provided for performance comparison
and tuning purposes.
- NONEMPTY
-
Optimizes queries by generating an MDX statement with NONEMPTYCROSSJOINs
of the sets of referenced dimensions on the ROWS axis.
Note: The
SET EMPTY command must be set to OFF (the default), to use this
option.
Under certain conditions, the NONEMPTY option delivers
the best performance for queries that reference low levels of multiple
dimensions because these queries usually yield very high numbers
of cells. However, NONEMPTYCROSSJOINs cannot be used if the
dimensions contain calculated members. In such cases the resulting
reports will be incorrect. (If this occurs, try the CROSSJOINOPTIMIZATION
ON.)
Before using this option, refer to the description of
the NONEMPTYCROSSJOIN function in the Microsoft Analysis Services documentation.
Tip: You
can change this setting from the Web Console by clicking Data
Adapters in the navigation pane, clicking the name of
a configured adapter, and choosing Change Settings from
the menu. The Change Settings pane opens.
Example: Accelerating Query Performance Using CROSSJOINOPTIMIZATION
Suppose
that you want to create an intermediate file containing the data
aggregated on the lowest levels for the dimensions TIME, PRODUCT,
CUSTOMER and STORE:
TABLE FILE SALES
SUM Sales_Count Store_Sales Store_Cost Unit_Sales
BY Month
BY Name
BY Store_Name
BY Product_Name
ON TABLE HOLD
ENDGiven the cardinalities of the involved levels:
(24, 10281, 25 and 1560, correspondingly) this request would never
be completed without CROSSJOIN optimization because Microsoft Analysis
Services software would have to instantiate an astronomical number
of cells: 9623016000. However, if you set CROSSJOINOPTIMIZATION
to NONEMPTY the request finishes within 30 seconds, resulting in
a HOLD file that contains 250983 records.
Example: Combining EMPTY OFF With CROSSJOINOPTIMIZATION NONEMPTY
The
SET EMPTY OFF command suppresses rows, or report lines, where all
the selected measure columns have empty values. For example, in
the following request,
TABLE FILE SALES
SUM Sales_Count Store_Sales Store_Cost Unit_Sales
BY Month
BY Name
BY Store_Name
ENDmost users would prefer to see on the report only
those combinations of stores and customers where Unit_Sales contains
a number reflecting actual sales (EMPTY OFF), rather than seeing
all possible combinations of stores and customers where the majority
of report lines probably contain a 0 or a dot in the Unit_Sales
column (EMPTY ON).
In EMPTY OFF mode, CROSSJOIN optimization
delegates the selection of the non-empty rows to the database engine.
x
The Adapter for SQL Server Analysis Services (SSAS)
supports:
-
JOIN commands. The Adapter for SQL Server Analysis
Services (SSAS) does not support direct JOINs from or to a cube.
Therefore, SQL JOINs using WHERE criteria are not supported. To
achieve a joined request, use the FOCUS MATCH FILE command or create
a HOLD file and include the HOLD file in the joined request.
-
SUM and PRINT commands with Measures dimensions. When
using these commands in a request, the verb used against the Adapter
for SQL Server Analysis Services (SSAS) does not affect the output,
which is always the value found in the cube.
Example: Using SUM and PRINT Commands in a Report Request
In
the following request, the PRINT verb is used, and SUM is the aggregator
for STORE_COSTS. However, the value displayed is always the value
stored in the cube or the specified measure at the intersection
of the dimension values, regardless of the verb used in the request.
TABLE FILE SALES
PRINT Store_Costs
BY City
END
The correct request produces the same report output:
TABLE FILE SALES
SUM Store_Costs
BY City
END
The partial output is:
City Store Cost
---- ----------
Albany 5,593.28
Altadena 2,239.71
Anacortes 641.93
Arcadia 2,045.73
Ballard 2,169.51