Adabas Reporting Considerations
Designers have great flexibility in coding the description of
the part of the Adabas structure that they want to access. These
topics describe the methods of file traversal that the Adapter for
Adabas uses to determine the relative advantages of different file descriptions.
xAdabas File Navigation Techniques
When you define specific hierarchical representations
of Adabas structures in Master Files, you specify the order in which
you want the Adapter for Adabas to retrieve records. This procedure
is called navigational logic and is usually part of the application
program. Navigation techniques using the JOIN command also work
this way.
xReferencing Subtrees and Record Retrieval
The Adapter for Adabas selects where to enter the subtree,
called the point-of-entry, and the subsequent navigational processing,
by analyzing the tree structure defined by your Master File (or
JOIN structure) and report request. The adapter determines the smallest
subtree that contains all the fields needed for retrieval to produce
a report.
The smallest subtree is composed of those segments that contain
fields referenced by the request, plus the minimum number of additional
segments required to connect all the files used in the request.
The adapter retrieves records only in segments in the referenced
subtree. Within the subtree, it retrieves records that contain fields
required for the report request or records that are needed to provide
the correct links between report fields.
The adapter always enters a database through the root segment
of the referenced subtree.
xSegment Retrieval Methodology
The Adapter for Adabas retrieves segments from top-to-bottom,
then left-to-right at each level of the hierarchy. It retrieves
all unique descendant segments before any non-unique descendant
segments.
This treatment of unique segments is consistent with a basic server principle:
for reporting purposes (though not for updating or file organization),
a unique child is logically a direct extension of its parent. This principle
is an important factor in selecting a structure that properly reflects
your Adabas file. The results of SUM and COUNT operations on fields
in child segments may depend on whether they have been declared
unique or non-unique. The server also treats missing segments differently,
depending on whether the segment is declared unique or non-unique.
x
If a segment is specified as unique (SEGTYPE=U or KU), the server regards
it as a logical extension of the parent segment. The Adapter for
Adabas automatically inserts default values (blanks for alphanumeric
fields and zeros for numeric fields) if the unique child segment
does not exist. As a result, unique segments are always present.
x
Syntax: How to Use Missing Non-Unique Segments
If
a segment is specified as non-unique (SEGTYPE=S or KM), select one
of three options for processing a record without descendant segments
SET ALL=all_option
where:
- all_option
Allows for the processing of records
with no descendant segments. Possible values are:
OFF which omits parent
instances that are missing descendant segments from the report.
OFF is the default value.
ON which includes
parent instances that are missing descendant segments in the report.
PASS which
includes parent instances that are missing descendant segments,
even when IF criteria exist to screen fields in the missing instances
of the descendant segment.
You can specify
SET ALL in a profile or procedure.
The examples in the following
topics describing the SET ALL command are based on the following
structure:
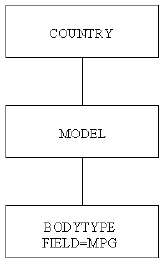
x
The default option (SET ALL=OFF) rejects a record if
the request calls for retrieval of a descendant segment and there
is no descendent segment present.
For example, assume you have a file in which the parent segment
is COUNTRY, which has a descendant segment named MODEL, which in
turn has a descendant segment named BODYTYPE. Using the SET ALL=OFF
option, the statement
COUNT BODYTYPE BY COUNTRY
does not print in the report the details of any country that
did not produce at least one bodytype of a model of a car.
x
The Adapter for Adabas displays the parent record, even
if it has no descendant segments. In this case, using the SET ALL=ON
option when processing the statement
COUNT BODYTYPE BY COUNTRY
displays the names of all countries and gives a count of zero
(0) bodytypes for those without descendant segments.
However, if the request has an explicit screening test on the
descendant segment, the absence of any descendant segments results
in test failure. For example, the request
COUNT BODYTYPE BY COUNTRY
IF MPG GT 22
excludes any country without any bodytype segments from the report.
x
The third option, SET ALL=PASS, allows parents without
a descendant segment to pass an explicit screening test on that
descendant segment. The request
COUNT BODYTYPE BY COUNTRY
lists all countries with or without bodytype segments. The request
COUNT BODYTYPE BY COUNTRY
IF MPG GT 22
includes records without any bodytype segments, and those with
an MPG greater than or equal to 22.
x
Selectively apply SET ALL=ON by adding the ALL prefix
to any field from the desired segment.
Reference the field either as a sort field (for example, BY ALL.COUNTRY
or ACROSS ALL.COUNTRY) or as a display field (WRITE ALL.COUNTRY).
As a result, the SET ALL=ON strategy is applied to any missing,
immediate, non-unique descendants of the segment containing the
ALL-prefixed field. The SET ALL=OFF option is in effect for all
other segments.
For example, in the request
COUNT MODEL AND BODYTYPE BY ALL.COUNTRY
the SET ALL=ON option applies to the country segment and its
descendant segments. Therefore, if there is a country without models
(and consequently without bodytypes), the report shows that country.
Any test condition on either the model or the bodytype segment nullifies
the effect of the ALL prefix.
The global SET ALL settings of ON and PASS take precedence over
the selective ALL prefix. The selective ALL prefix is effective
only when the global setting is OFF, either explicitly or by default.
xAdabas Selection Considerations
The Adapter for Adabas analyzes all selection criteria
that apply to a specific report request and uses the criteria to
minimize its search for data. If a record fails any of the selection
tests, the server does
not attempt to retrieve any descendant records. Retrieval continues
with the next record in the parent segment. If there is no other
record in that parent segment and it is not the root of the Master
File, The server moves
back up to the next record in the previous segment.
The selection tests that you impose on a high-level segment are
much more efficient at reducing I/O operations than criteria imposed
on lower-level segments. If you know in advance which selection
criteria are likely to be used most frequently, design the Master File
to take advantage of the hierarchical structure in the Adapter for Adabas.
xSelection Order in the Access File
When a report request contains multiple optimizable
selection tests, the order of descriptors in the Access File determines
the order in which the server applies the selection tests. The server
issues a Read Logical (RL) call using the first descriptor listed
in the Access File that participates in a selection test.
Therefore, for efficient processing you should describe the most
restrictive descriptor at the beginning of its segment in the Access
File. The order of descriptors in the Master File has no effect
on selection processing.
x
Syntax: How to Use RECORDLIMIT and READLIMIT
For
any request, you may limit the number of Adabas records retrieved
from the database and the number of read operations performed. Use
the RECORDLIMIT and READLIMIT parameters to impose these limitations
by adding the following conditions to a report request
{WHERE|IF} RECORDLIMIT {EQ|IS} n {WHERE|IF} READLIMIT {EQ|IS} n where:
- n
Is the number of records or read operations at which you
want to limit the search.
You add these
conditions to any report request, or incorporate them into file
security through the DBA facility.
Consider the following
example
TABLE FILE VEHICLES
PRINT PERSONNEL_ID MAKE MODEL YEAR
WHERE RECORDLIMIT EQ 5
END
which produces this report:
PAGE 1
PERSONNEL_ID MAKE MODEL YEAR
------------ ---- ----- ----
11500330 CITROEN BX LEADER 85
11400313 ALFA ROMEO SPRINT GRAND PRIX 84
30034217 AUSTIN MINI 80
30034228 TALBOT SOLARA 83
30008427 AUSTIN MINI 80
Notice
that only five records are reported as requested.
x
Syntax: How to Use Optimization of the FIND Call Using Non-Descriptor Fields
Tip: You
can change this setting manually or from the Web Console by clicking Adapters on
the menu bar, clicking a configured adapter, and choosing Change
Settings from the right-click menu. The Change Settings
pane opens.
It is possible to use non-descriptor fields as
search criteria and have the calls to Adabas use the search buffer
rather than read through the entire database.
The Adapter for Adabas provides
improved optimization by allowing the search buffer to be generated
using non-descriptor fields. This optimization occurs whenever CALLTYPE=FIND
is specified in the Access File and you include an IF or WHERE test referencing
a non-descriptor field in your report request.
It may prove
to be more efficient to alter your retrieval strategy and perform
a Read Physical (L2) call when large amounts of data exist. A SET
command is provided for changing the default Adabas call when selecting
non-descriptor fields.
ENGINE ADBSINX SET NDFIND {ON|OFF}
where:
- ENGINE
-
Indicates the adapter. You can omit this value if you previously
issued the SET SQLENGINE command.
-
ON
-
Causes the search buffer to be generated with any field (non-descriptor and/or
descriptor field). ON is the default value.
- OFF
-
Causes the search buffer to be generated with only descriptor
fields. If the request does not use any descriptor field, the Read
Physical call is generated.
This
command applies only if CALLTYPE=FIND is specified in the Access File.
xUsing the JOIN Command to Process Multiple Files
You can JOIN Adabas databases defined to the server to
other Adabas databases or to any other fully joinable database that the server can
read. Each JOIN creates a parent-child relationship. The parent
field is called the host or from field. The child field is
called the cross-referenced or to field.
You can JOIN to Adabas databases if the cross-referenced field
is one of the following:
- A descriptor field.
- A superdescriptor defined with TYPE=SPR or NOP in the Access
File.
- A subdescriptor defined with TYPE=NOP in the Access File.
In every case, in the Access File, the cross-referenced segment
must specify ACCESS=ADBS.
If CALLTYPE=RL is specified for the cross-referenced segment,
the host field can be joined to the high-order portion of a descriptor,
superdescriptor, or subdescriptor.
When an Adabas file is the host file, the host field is one of
the following:
- A non-recurring field (ACCESS=ADBS).
- A field in a periodic group (ACCESS=PE).
- A multi-value field (ACCESS=MU).
The Adapter for Adabas also supports DEFINE-based JOINs. Up to
16 JOINs can be in effect at one time.
Example: Multi-field JOIN and Short-to-Long JOIN Capability
For
a multi-field JOIN, the number of fields used in the JOIN must be
the same for both the host and the cross-referenced files. The cross-referenced
fields must describe the left-most portion of a superdescriptor
defined to the server using the GROUP attribute. Consider the following
example.
JOIN FLDA AND FLDB IN ADBS1 TO KEY1 AND KEY2 IN ADBS2 AS J1
For
the short-to-long JOIN, the cross-referenced field must be a descriptor, subdescriptor,
or superdescriptor, or a field that describes the left-most portion
of a GROUP superdescriptor.
xAdabas Optimization With Null-Suppression for CALLTYPE=RL
In the Adapter for Adabas, optimization refers to using
an index to retrieve the answer set. To ensure data integrity and
complete answer sets, the Adapter for Adabas will perform optimization
when all:
- Non-referenced component fields of a superdescriptor are not null-suppressed
(NU=NO in the Access File).
- Component fields of a superdescriptor that contain null-suppressed
fields (NU=YES in the Access File) are used in the selection criteria.
If a field is null-suppressed in Adabas (NU=YES in the Access
File), any superdescriptor that uses this field has no entry on
the inverted list when this field is blank (alphanumeric) or zero
(numeric).
Master File With a Three-Field Superdescriptor
GROUP=SUPERG ,ALIAS=S1 ,USAGE=A9 ,ACTUAL=A9 ,INDEX=I ,$
FIELD=FLD1 ,ALIAS=AA ,USAGE=A3 ,ACTUAL=A3 ,$
FIELD=FLD2 ,ALIAS=AB ,USAGE=A3 ,ACTUAL=A3 ,$
FIELD=FLD3 ,ALIAS=AC ,USAGE=A3 ,ACTUAL=A3 ,$
Access File With a Three-Field Superdescriptor
FIELD=SUPERG ,TYPE=SPR,$
FIELD=FLD1 ,TYPE= ,NU=YES ,$
FIELD=FLD2 ,TYPE= ,NU=NO ,$
FIELD=FLD3 ,TYPE= ,NU=YES ,$
In order to optimize a selection test against a superdescriptor
with null-suppression, you must explicitly reference the null-suppressed
field in the superdescriptor. If you do not reference the null-suppressed
field and the field has no data, there is no record in the index and
optimization would return no records. To ensure correct results, the server will
not optimize the selection test if the null-suppressed field is
not referenced.
For more information about null-suppression and how it affects
data retrieval, see your Software AG documentation.
xAdabas Optimization on Group Fields
If a report request contains IF or WHERE selection tests
against one or more fields that describe the left-most portion of
a GROUP descriptor, the Adapter for Adabas combines this request
into a test that uses the superdescriptor for greater efficiency.
If any of the component (or parent) fields of the superdescriptor
are defined to Adabas with null-suppression, be sure to note this
information in the Access File to ensure accuracy of reads.
For example, consider the following Master File extract:
GROUP=SUPERD ,ALIAS=SD ,USAGE=A8 ,ACTUAL=A8 ,INDEX=I ,$
FIELD=PART1 ,ALIAS=P1 ,USAGE=A4 ,ACTUAL=A4 ,$
FIELD=PART2 ,ALIAS=P2 ,USAGE=A4 ,ACTUAL=A4 ,$
If, in a report request, you include the following two tests,
WHERE PART1 EQ 'ABCD'
WHERE PART2 EQ 'EFGH'
these two tests are equivalent to the following syntax:
WHERE SUPERD EQ 'ABCD/EFGH'
This combination uses the superdescriptor's inverted list and
optimizes the Adabas call. This optimization is performed only if
all null-suppressed (NU=YES) superdescriptor components are explicitly
referenced in IF or WHERE tests.
xTest on Group Field With Numerics
If you are testing on a group that contains numeric
fields, the test must contain the sign byte. The Adapter for Adabas
passes only one value per numeric field, based on the preferred
sign values in Adabas. A sign value of F is passed for positive numbers
and a sign value of D is passed for negative numbers. This sign
value reduces the number of calls sent to Adabas and also eliminates
the need for Adabas to perform any logical sign translation.
For example:
GROUP=GROUP1 ,ALIAS=S1 ,USAGE=A9 ,ACTUAL=A14 ,INDEX=I ,$
FIELD=FLD1 ,ALIAS=AA ,USAGE=A3 ,ACTUAL=A3 ,$
FIELD=FLD2 ,ALIAS=AB ,USAGE=P3 ,ACTUAL=P3 ,$
FIELD=FLD3 ,ALIAS=AC ,USAGE=A3 ,ACTUAL=A3 ,$
In a report request, you must include the sign for the P3 field:
Mainframe platforms:
WHERE GROUP1 EQ 'ABC/123F/XYZ'
Non-mainframe platforms:
WHERE GROUP1 EQ 'ABC/123/XYZ'