Load your data, as detailed in Introducing WebFOCUS RStat.
x
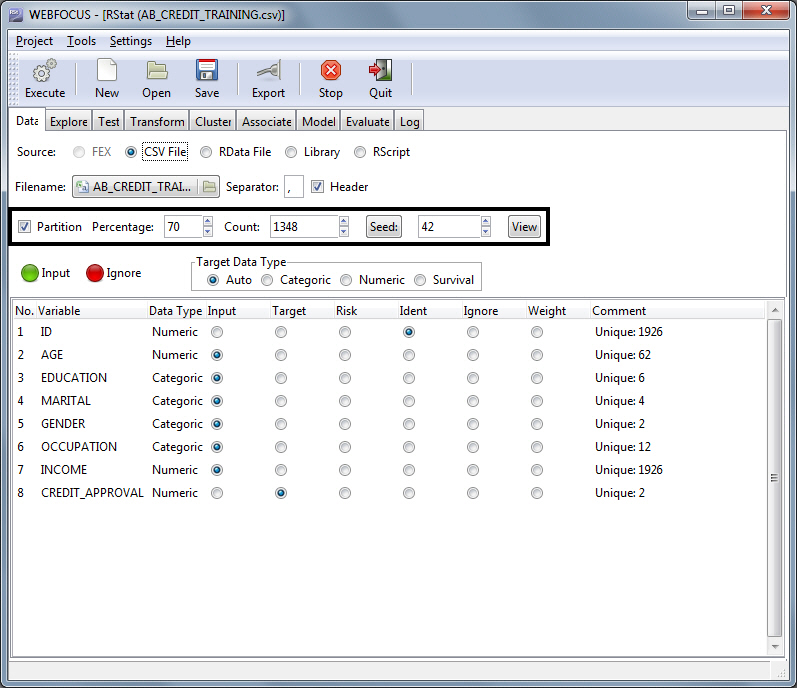
RStat provides random sampling. You can divide your
data set into a training data set and a testing data set. The training
data set will be used to build the model. The testing data set,
also called the evaluation data set, can be used by the model evaluation
techniques to test how well the model predicts.
Define the proportion of data to be included in each data set
and the seed to be used to generate the random sample.
Note:
- By default,
when new data is loaded, Sampling is turned on.
- You can define
the size of the training data set using either the Percentage or
Count controls. Notice that they are tied together. As you change
the value of the Percentage, the Count will automatically be updated
with the actual sample size that will be created.
- To replicate
the same sample, use a constant seed value. If you would like to
vary the contents of the random sample, modify the seed value.
x
For each of the variables within
your data set, you can define the role it should play in the model
by clicking the appropriate column within the Variable Grid.
RStat automatically assigns roles to
variables based on the following variable prefixes.
|
Prefix
|
Role
|
|---|
|
ID
|
Identifier
|
|
IGNORE
|
Ignored
|
|
IMP
|
Imputed
|
|
RISK
|
Risk measure
|
You can have one Target and one Risk variable.
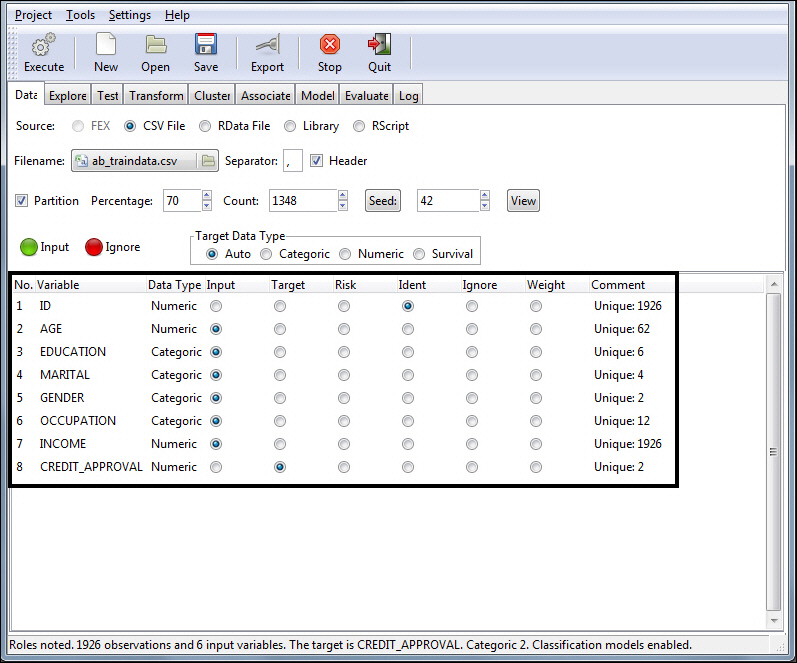
You can override these default settings by clicking the appropriate
role for each of your variables.
xSetting Variable Roles for Groups
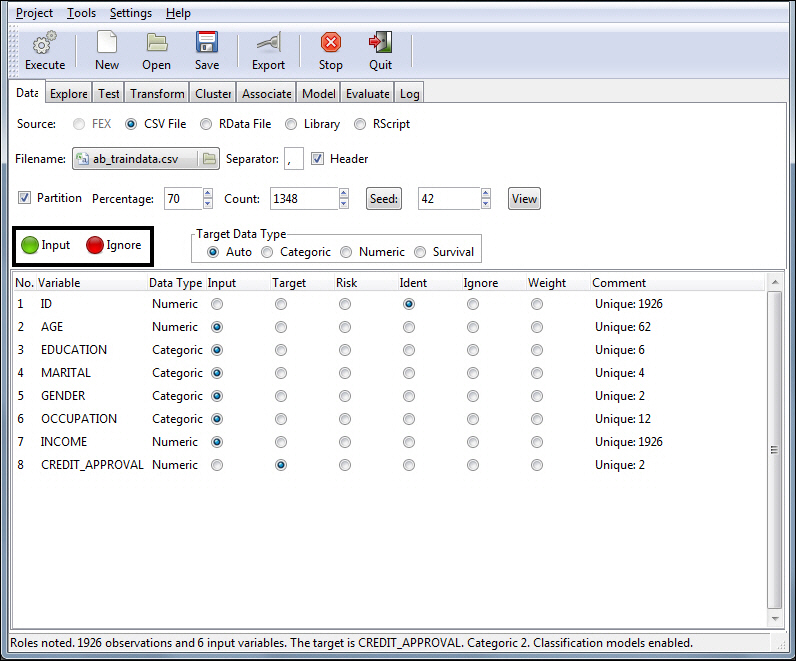
You can set a group of variables to a single role using the Input
and Ignore buttons by:
- Selecting
the variables to be set from the Variable Grid. To select multiple variables,
hold down the Ctrl key while clicking each variable, or the Shift
key to define a range. You can select all variables within the grid
by clicking one of the variables and then pressing Ctrl+A.
- Clicking the
green Input button to define all selected variables as input or
the red Ignore button to define all selected variables as ignored.
This defines a portion to be used as training data and opens with
the selected data set loaded. RStat presents nine tabs that reflect
the standard modeling workflow. The Data tab shows the variables
and the roles each will play in building the model.
x
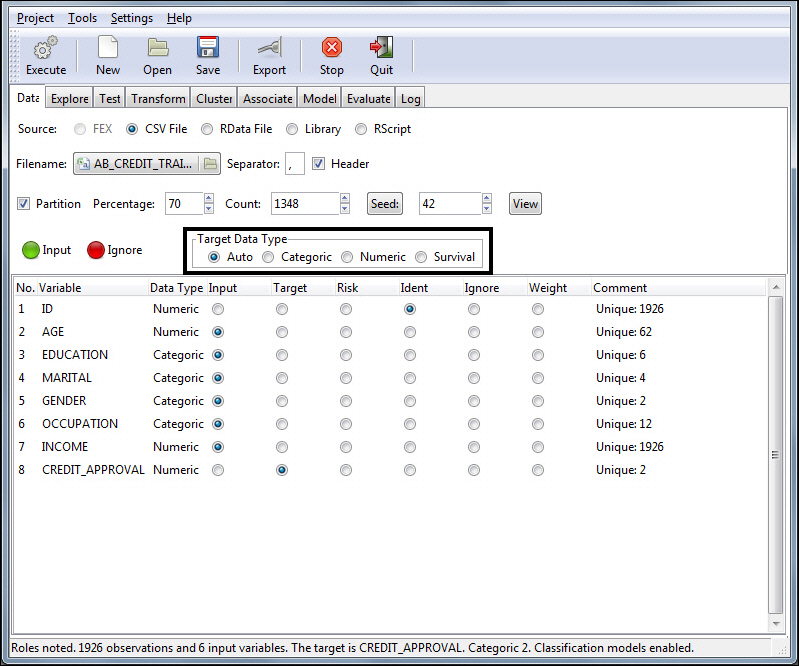
The data type of the target variable determines the type of modeling
available and the specific algorithms that will be used within the
modeling process. The data type is defined based on the type of
data RStat identifies and the quantity of unique values found in
the actual data. In RStat, data types are defined as:
-
Auto. This
option is selected by default.
-
Categoric. Any
character data or any numeric data with 10 or less unique values.
-
Numeric. Any
numeric data with more than 10 unique values.
-
Survival. Allows
the user to run a Survival Model (that is, Cox Proportional Hazards
or Parametric). The Time and Status roles must be assigned to two
variables in the data set in order to run the survival techniques.
Note: The target setting does not change the actual data
within the data grid. It will change only the way the target data
is used when the model is built.
x
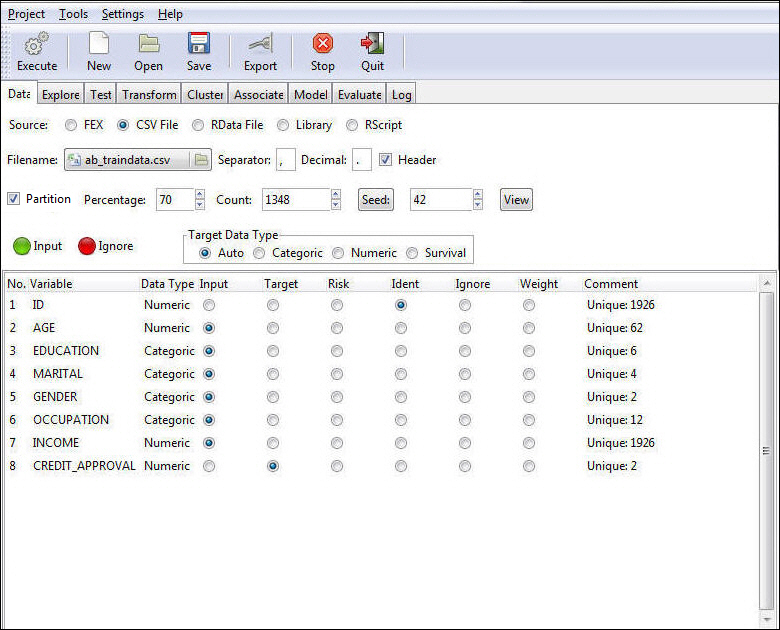
Once you have set or confirmed the Sampling, Data roles, and
Target type, click Execute from the RStat
toolbar to pass these settings to RStat.
Notice that the status bar will display the:
- Number of
rows of data.
- Number of
Input variables.
- Target variable
and type that will be used for modeling.