|
|
|
Using the OCCURS Attribute
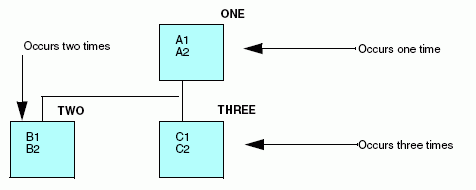
The OCCURS attribute is an optional segment attribute used to describe records containing repeating fields or groups of fields. Define such records by describing the singly occurring fields in one segment, and the multiply occurring fields in a descendant segment. The OCCURS attribute appears in the declaration for the descendant segment.
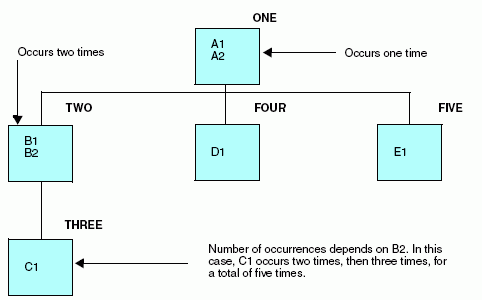
You can have several sets of repeating fields in your data structure. Describe each of these sets of fields as a separate segment in your data source description. Sets of repeating fields can be divided into two basic types: parallel and nested.
|
|
|
Syntax: How to Specify a Repeating Field
OCCURS = occurstype
Possible values for occurstype are:
- n
-
Is an integer value showing the number of occurrences (from 1 to 4095).
- fieldname
-
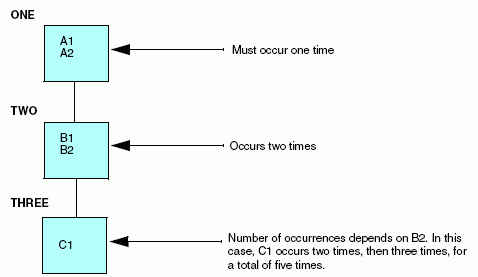
Names a field in the parent segment or a virtual field in an ancestor segment whose integer value contains the number of occurrences of the descendant segment. Note that if you use a virtual field as the OCCURS value, it cannot be redefined inside or outside of the Master File.
- VARIABLE
-
Indicates that the number of occurrences varies from record to record. The number of occurrences is computed from the record length (for example, if the field lengths for the segment add up to 40, and 120 characters are read in, it means there are three occurrences).
Place the OCCURS attribute in your segment declaration after the PARENT attribute.
When different types of records are combined in one data source, each record type can contain only one segment defined as OCCURS=VARIABLE. It may have OCCURS descendants (if it contains a nested group), but it may not be followed by any other segment with the same parent. There can be no other segments to its right in the hierarchical data structure. This restriction is necessary to ensure that data in the record is interpreted unambiguously.
|
|
|
Example: Using the OCCURS Attribute
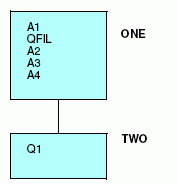
Consider the following simple data structure:
A |
B |
C1 |
C2 |
C1 |
C2 |
You have two occurrences of fields C1 and C2 for every one occurrence of fields A and B. Thus, to describe this data source, you place fields A and B in the root segment, and fields C1 and C2 in a descendant segment, as shown here:
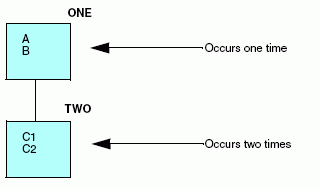
Describe this data source as follows:
FILENAME = EXAMPLE1, SUFFIX = FIX, $ SEGNAME = ONE, SEGTYPE=S0, $ FIELDNAME = A, ALIAS=, USAGE = A2, ACTUAL = A2, $ FIELDNAME = B, ALIAS=, USAGE = A1, ACTUAL = A1, $ SEGNAME = TWO, PARENT = ONE, OCCURS = 2, SEGTYPE=S0, $ FIELDNAME = C1, ALIAS=, USAGE = I4, ACTUAL = I2, $ FIELDNAME = C2, ALIAS=, USAGE = I4, ACTUAL = I2, $