|
|
|
Joining From Several Segments in One Host Data Source
In an application, you may want to use the same cross-referenced segment in several places in the same data source. Suppose, for example, that you have a data source named COMPFILE that maintains data on companies you own:
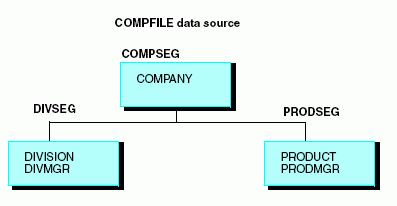
The DIVSEG segment contains an instance for each division and includes fields for the name of the division and its manager. Similarly, the PRODSEG segment contains an instance for each product and the name of the product manager.
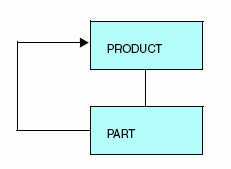
Retrieve personal information for both the product managers and the division managers from a single personnel data source, as shown below:
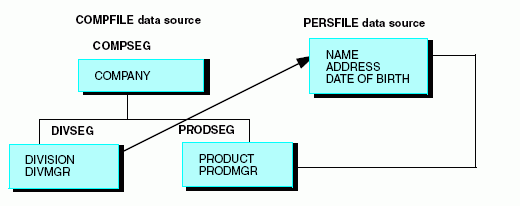
You cannot retrieve this information with a standard Master File defined join because there are two cross-reference keys in the host data source (PRODMGR and DIVMGR) and in your reports you will want to distinguish addresses and dates of birth retrieved for the PRODSEG segment from those retrieved for the DIVSEG segment.
A way is provided for you to implement a join to the same cross-referenced segment from several segments in the one host data source. You can match the cross-referenced and host fields from alias to field name and uniquely rename the fields.
The Master File of the PERSFILE could look like this:
FILENAME = PERSFILE, SUFFIX = FOC, $ SEGNAME = IDSEG, SEGTYPE = S1, $ FIELD = NAME, ALIAS = FNAME, FORMAT = A12, INDEX=I, $ FIELD = ADDRESS, ALIAS = DAS, FORMAT = A24, $ FIELD = DOB, ALIAS = IDOB, FORMAT = YMD, $
You use the following Master File to join PERSFILE to COMPFILE. Note that there is no record terminator ($) following the cross-referenced segment declaration (preceding the cross-referenced field declarations).
FILENAME = COMPFILE, SUFFIX = FOC, $ SEGNAME = COMPSEG, SEGTYPE = S1, $ FIELD = COMPANY, ALIAS = CPY, FORMAT = A40, $ SEGNAME = DIVSEG, PARENT = COMPSEG, SEGTYPE = S1, $ FIELD = DIVISION, ALIAS = DV, FORMAT = A20, $ FIELD = DIVMGR, ALIAS = NAME, FORMAT = A12, $ SEGNAME = ADSEG, PARENT = DIVSEG, SEGTYPE = KU, CRSEGNAME = IDSEG, CRKEY = DIVMGR, CRFILE = PERSFILE, FIELD = NAME, ALIAS = FNAME, FORMAT = A12, INDEX = I,$ FIELD = DADDRESS, ALIAS = ADDRESS, FORMAT = A24, $ FIELD = DDOB, ALIAS = DOB, FORMAT = YMD, $ SEGNAME = PRODSEG, PARENT = COMPSEG, SEGTYPE = S1, $ FIELD = PRODUCT, ALIAS = PDT, FORMAT = A8, $ FIELD = PRODMGR, ALIAS = NAME, FORMAT = A12, $ SEGNAME = BDSEG, PARENT = PRODSEG, SEGTYPE = KU, CRSEGNAME = IDSEG, CRKEY = PRODMGR, CRFILE = PERSFILE, FIELD = NAME, ALIAS = FNAME, FORMAT = A12, INDEX = I,$ FIELD = PADDRESS, ALIAS = ADDRESS, FORMAT = A24, $ FIELD = PDOB, ALIAS = DOB, FORMAT = YMD, $
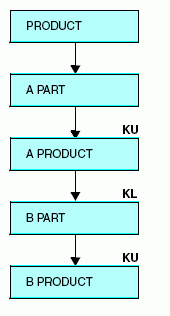
DIVMGR and PRODMGR are described as CRKEYs. The common alias, NAME, is automatically matched to the field name NAME in the PERSFILE data source. In addition, the field declarations following the join information rename the ADDRESS and DOB fields to be referred to separately in reports. The actual field names in PERSFILE are supplied as aliases.
Note that the NAME field cannot be renamed since it is the common join field. It must be included in the declaration along with the fields being renamed, as it is described in the cross-referenced data source. That it cannot be renamed is not a problem, since its ALIAS can be renamed and the field does not need to be used in reports. Because it is the join field, it contains exactly the same information as the DIVMGR and PRODMGR fields.
The following conventions must be observed:
- The common join field FIELDNAME or ALIAS in the host data source must be identical to its FIELDNAME in the cross-referenced data source.
- The common join field should not be renamed, but the alias can be changed. The other fields in the cross-referenced segment can be renamed.
- Place field declarations for the cross-referenced
segment after the cross-referencing information in the Master File
of the host data source, in the order in which they actually occur
in the cross-referenced segment. Omit the record terminator ($)
at the end of the cross-referenced segment declaration in the host
Master File, as shown:
SEGNAME = BDSEG, PARENT = PRODSEG, SEGTYPE = KU, CRSEGNAME = IDSEG, CRKEY = PRODMGR, CRFILE = PERSFILE, FIELD = NAME, ALIAS = FNAME, FORMAT = A12 ,INDEX=I, $ FIELD = PADDRESS, ALIAS = ADDRESS, FORMAT = A24 , $ FIELD = PDOB, ALIAS = DOB, FORMAT = YMD , $