Clustering is a method of organizing objects into distinct groups or clusters based on their similarities. There are different types of clustering methods, including:
Each option uses different criteria to sort objects into groups for the purpose of analysis. For example, you can determine the degree of association between two objects. This allows you to discover unique structures in data, which would otherwise be unexplained.
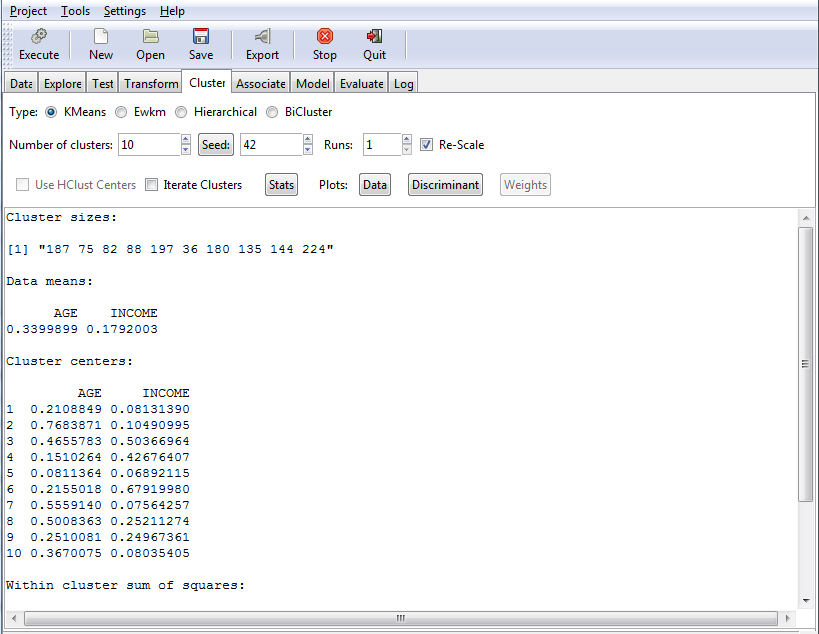
The Cluster tab enables you to use various clustering techniques to group data or objects. The results of a KMeans clustering algorithm are shown in the following image.
The different types of clustering algorithms include:
A partitioning method that is best suited for large amounts of data. It creates a group of mutually exclusive, unique clusters, and then returns an index of those clusters. It then presents the means, or averages, of those clusters. The value of k represents each unique cluster.
Used to cluster high-dimensional data, Ewkm outputs the weight of each variable in each cluster.
A method of cluster analysis that builds a hierarchy of clusters. You can create a dendrogram, show statistics (which displays the data averages), plot the data, or create a discriminant plot. Using an agglomerative, or bottom up, approach, this method is based on matching subsequent clusters to originating clusters, which are based on a single observation.
Also known as co-clustering or two-mode clustering, BiCluster is a technique that is employed during data mining. It allows the rows and columns of a matrix to be clustered simultaneously. The result of the model shows the number of clusters and their respective rows and columns.
| WebFOCUS |